2017년 Google Brain의 Geoffrey E. Hinton이 발표한 Object Recognition 분야의 새로운 접근방법을 제안한 논문이다. 기존의 Object Recognition모델들은 Convolution Network를 기반으로 설계되어있다. Convolution Network는
feature extracting - maxpooling로 이루어져있다. 여기서maxpooling의 문제점을 지적하며 새로운 기법을 적용시키는데 그것이 바로 Capsule 간의 routing by agreement 이다. 차근차근 리뷰를 해보록 하겠다.
Reference
- Dynamic Routing Between Capsules 원본 논문
- 시카고 대학 Dr Charles martin 의 유투브 동영상
- Hands-on Machine Learning 저자 Aurélien Géron 의 유투브 동영상
- 논문 저자 중 한명인 Sara Sabour 의 유투브 동영상
- jayhey’s Blog
- CapsNet 구현코드1 Pytorch 구현
- CapsNet 구현코드2 Pytorch 구현
Capsule Network
Capsule Network는 Object Recognition 분야에서 강력한 Object Segmentation 능력을 보여주는 새로운 접근 방법을 제시한 논문이다. 현재 대부분의 Object Recognition Network들은 Convolution Network로 이루어져있다. 아래 그림은 Object Recognition의 역사를 보기쉽게 정리해둔 이미지인데 한번 쭉 훑어보길 추천한다.
===== Object Recognition History 펼치기 =====

논문의 저자인 Geoffrey E. Hinton 박사는 Convolution Network의 단점을 비난하며 Capsule Network에 대한 설명을 시작하는데, 그렇다면 Convolution Nework는 도대체 어떤 단점을 갖고있고 이러한 단점을 Capsule Network로 어떻게 극복을 하였는지 알기 위해 서는 우선 Convolution Network의 특징에 대해서 알아야한다.
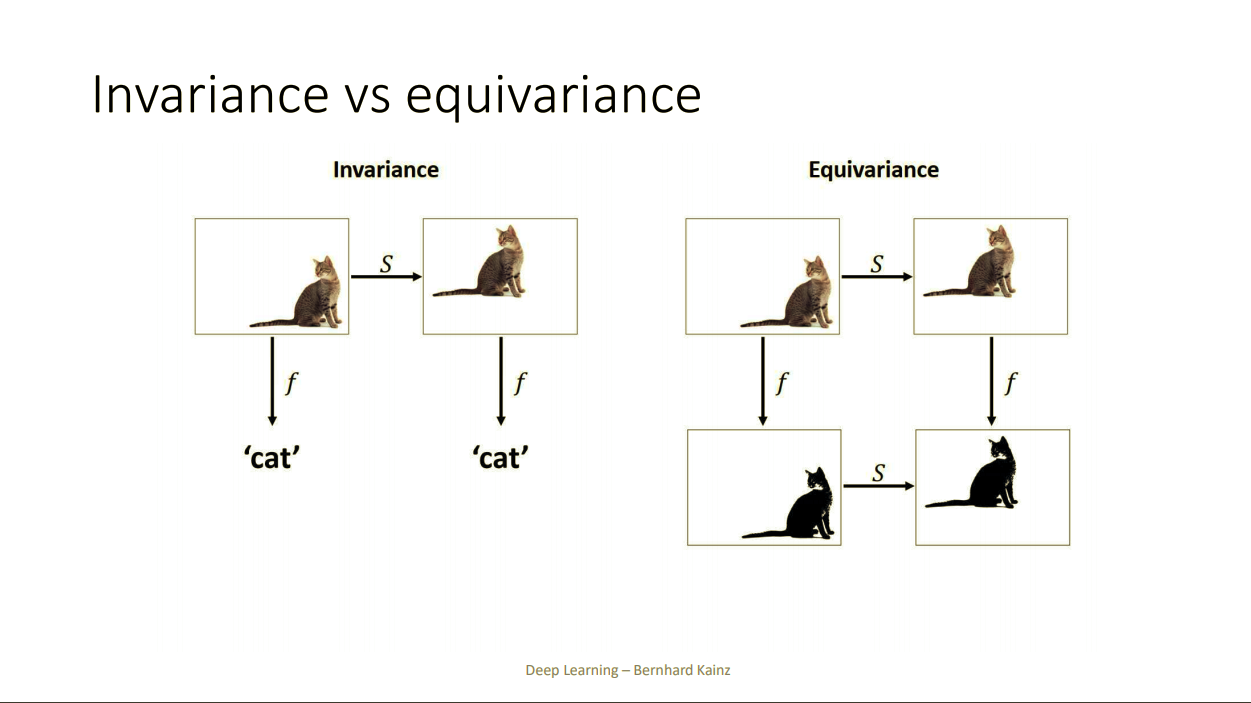
Invariance VS Equivariance
Convolution Network의 특징을 파악하기전 Invariance 와 Equvariance에 대한 설명을 하고 넘어가겠다. Invariance와 Equvariance는 기함수, 도함수 처럼 어떤 함수의 특징을 설명하는 단어이다. 자세한 설명을 원한다면 이 동영상을 시청하고 오는것을 추천한다.
Invariance와 Equvariance는 마치 음수와 양수처럼 서로 상반된이름을 가지고 있지만 반대되는 개념이 전혀아니다. 그냥 그 함수의 특징을 설명하는 단어다.
Invariance
Invariance는 input X에 약간의 변형을 가해도 같은 결과값을 출력해주는 함수를 말한다. 예를들어 고양이를 인식하는 함수가 있다고 가정해보자. 이 함수에 고양이 사진을 넣었을 때 고양이가 있으면 1을 출력해주고 없다면 0을 출력해준다고 하자.

$S_v$는 Shift Matrix로 X에 $S_v$를 곱해서 고양이를 다른 위치로 이동시킴
분명히 오른쪽 고양이와 왼쪽고양이는 다른 사진이지만 동일한 값을 출력해준다. 이러한 함수의 특징을 Invariance 한 함수다 라고 한다.
Equvariance
Equvariance는 어떤함수에 input X를 넣고 얻은 결과값에 어떤 변형을 준 결과와 input X에 같은 변형을 준 결과를 함수에 넣고 나온 결과가 같은 함수를 의미한다. 설명을 글로하면 말이 길어지는데 쉬운 예제로 $f(x) = 3x$ 를 생각하면 쉽게 이해할 수 있다.
\[f(1) = 3\\ f(1 \times 3) = 9\\ f(1) \times 3 = 9\]
이번에는 고양이면 1, 아니면 0을 출력해주는 함수가 아닌 고양이사진을 넣으면 고양이인 부분은 1, 고양이가 아닌 부분은 0인 이미지를 출력해주는 함수가 있다고 하자.
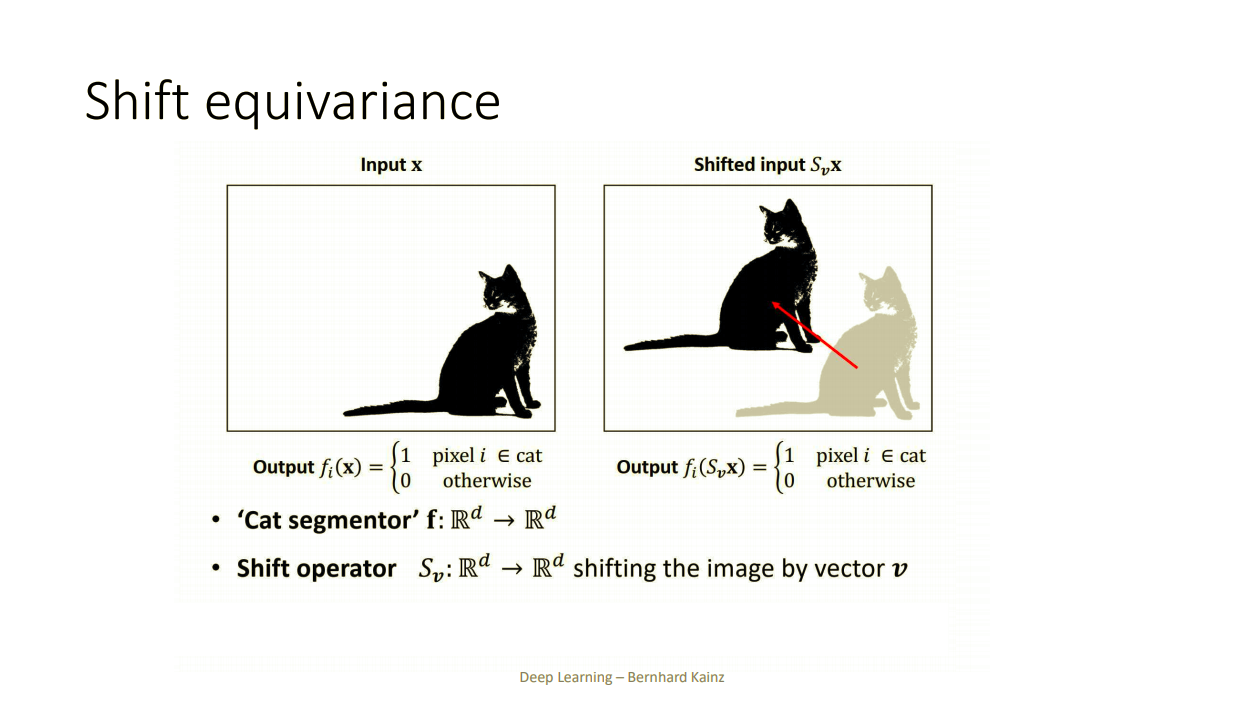
이렇게 변형된 input을 넣으면 변형된 그대로의 output이 나오는 함수를 equvariance 한 함수다 라고한다.
Convolution Network
본격적으로 CNN의 특징에 대해서 알아보겠다. CNN은 흔히 translation invariance 함수라고 말한다. 왜냐하면 당연하게도 같은 라벨의 이미지라면 위치나 구성이 달라졌다해도 구별을 잘 하기 때문이다. CNN이 translation invariance 한 특징을 가질 수 있게된 이유 중 하나는 바로 Max-pooling 때문이다.
ConvNet의 특징
CNN은 2가지 프로세스로 구성되어있다.
- Feature Extrating
- Subsampling(Max-pooling)
Feature Extrating 프로세스는 Equvariance 한 특성을 유지하는데, Subsapling에서 invariance 한 특성이 나오게된다.
Subsampling
CNN은 subsampling을 통해 local translation invariance를 얻게되는데
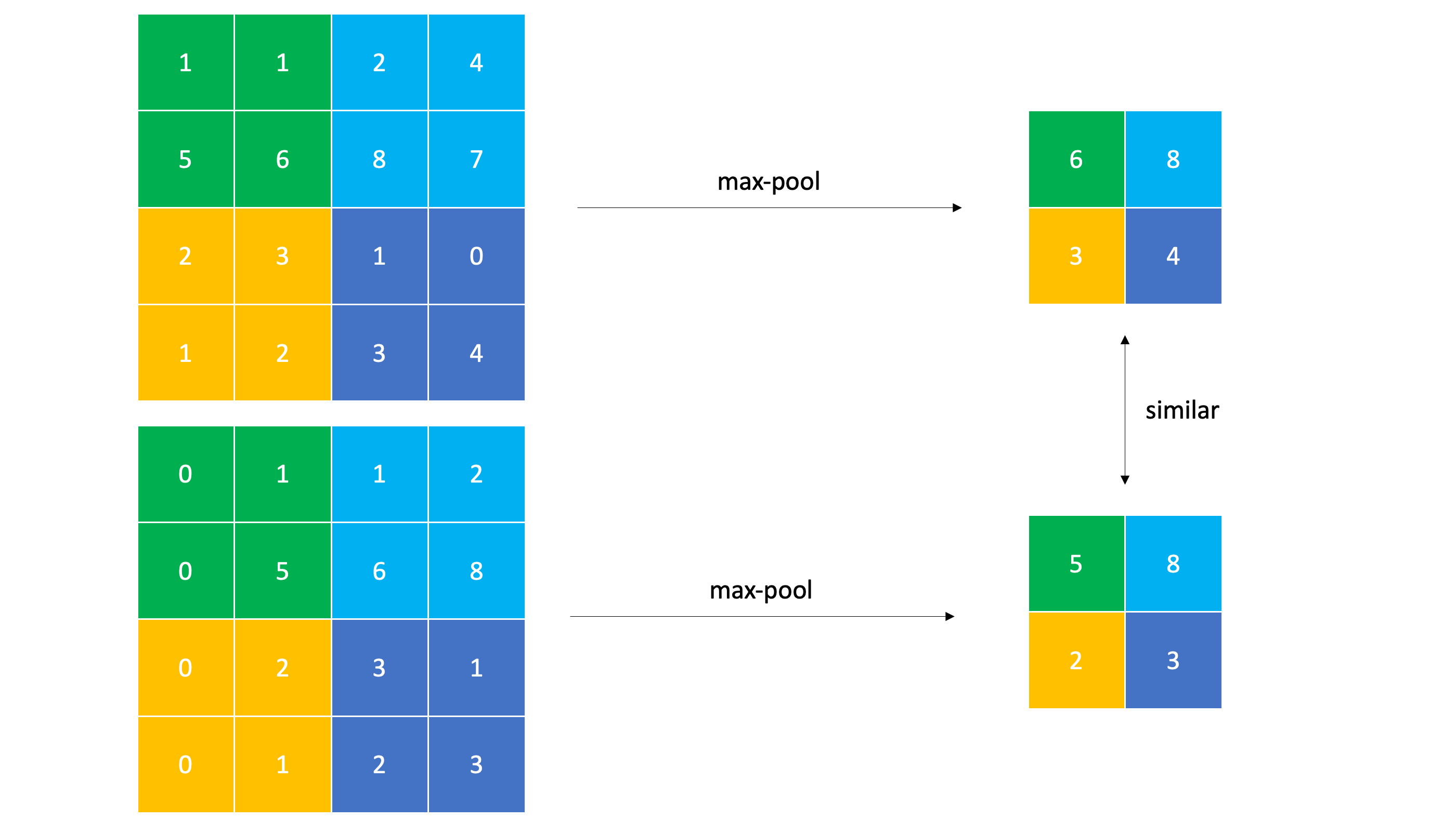
위의 matrix를 오른쪽으로 한칸씩 밀어낸 아래쪽의 matrix를 subsampling하면 비슷한 결과값이나온다. 즉 비슷한 input 이미지가 들어왔을 때 subsampling을 하게되면 비슷한 subsampled matrix 가 나오게되고 이러한 feature extrating-subsampling층을 깊게 쌓으면 쌓을 수록 결국 마지막엔 같은 결과 나오게된다. 이러한 특성 때문에 CNN은 input image가 변해도 동일한 결과값을 뽑아낼 수 있기 때문에 invariance하다 라고 말할 수 있는 것이다. 만약 CNN에 Max-pooling을 하지 않는다면 일반 DNN으로 CNN과 비슷한 성능을 낼 수 있게 될 것이다.
ConvNet의 한계
subsampling은 local invariance를 보장한다. 그런데 만약 이미지가 subsampling이 local하게 감당할 수 있는 범위를 벗어난다면 어떻게 될까? Rotate Transformation을 한번 보자.
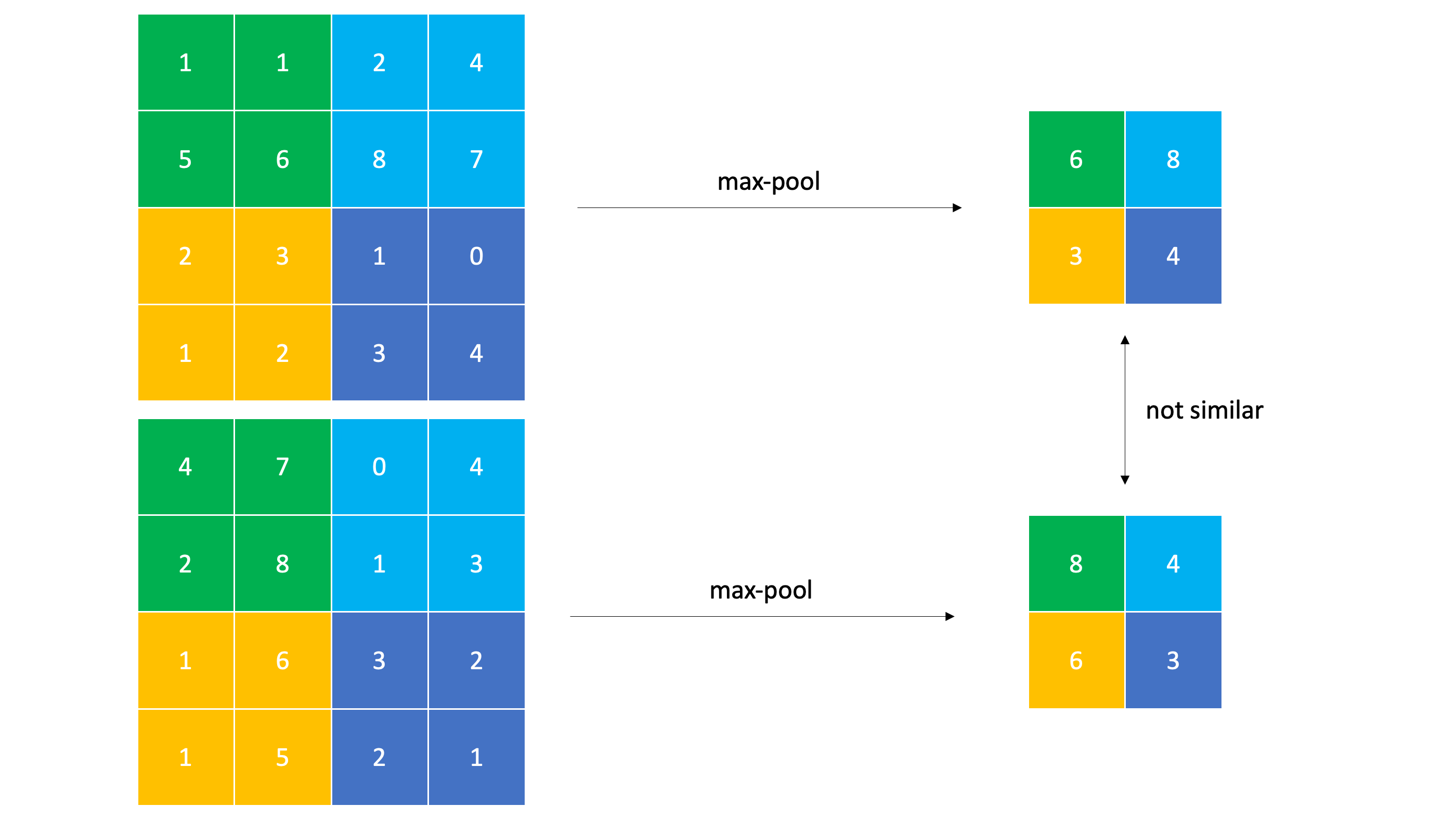
위의 matrix에서 반시계방향 90도 회전을 시킨 matrix는 전혀다른 subsampled matrix를 뽑아낸다. subsampling이 감당할 수 있는 작은 범위의 회전에서는 비슷한 값이 나오겠지만, 실제로 local한 범위를 벗어나는 회전변화에 CNN은 매우 취약한 모습을 보여준다.
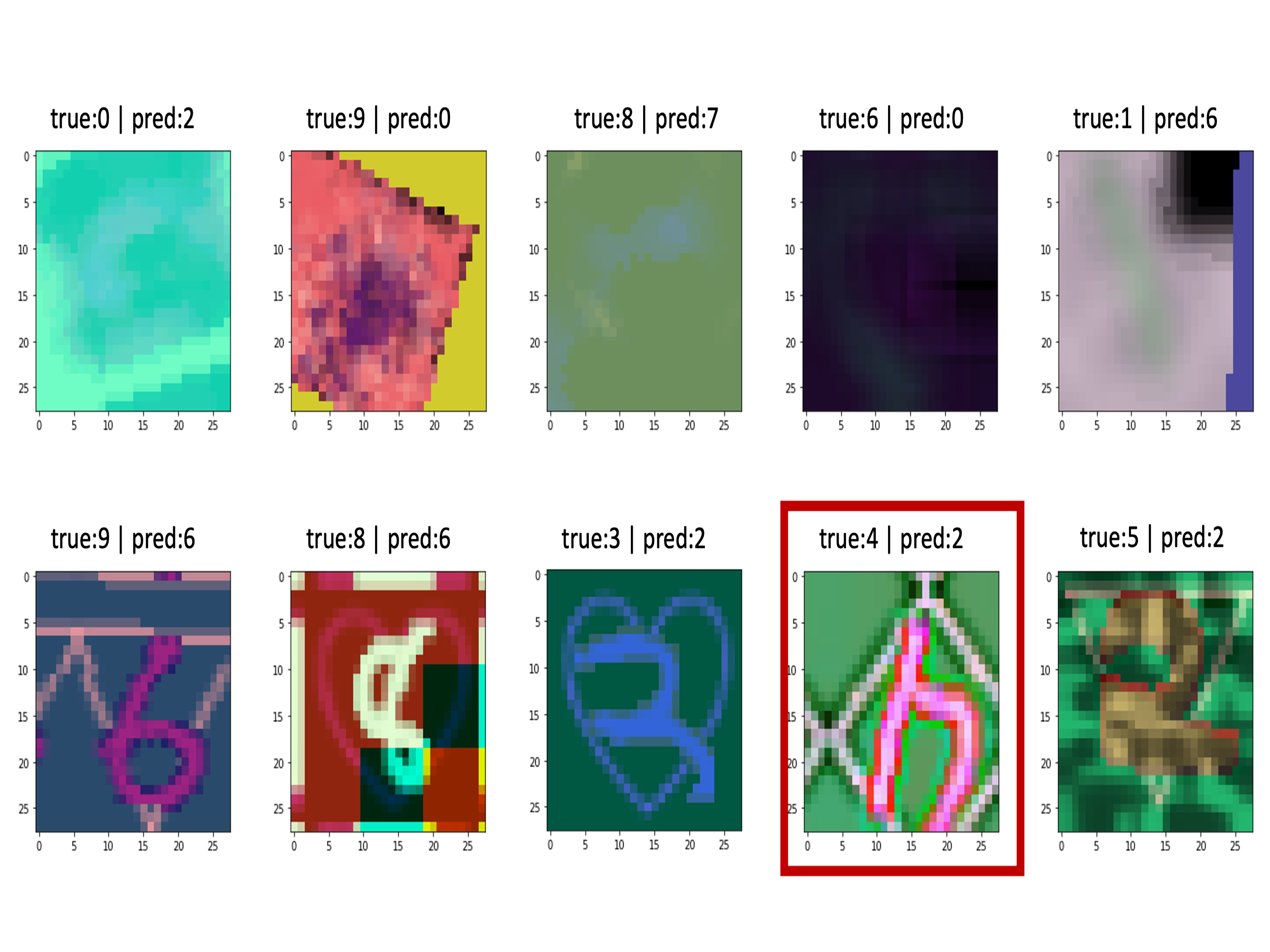
이 이미지는 이전에 VGGnet으로 3D MNIST data predict했을 때 나온 오답 이미지이다. 빨간 박스의 4를 보면 누가봐도 4인데 VGG의 invariance를 벗어난 회전이기 때문에 이상한 예측을 하게 된 것이다. CNN은 subsampling으로 뽑은 가장 activate한 특징만을 가지고 예측을 했지, feature간의 spatial relationship을 전혀 고려하지 않았기 때문에 이러한 오답이 나오는 것이다. 이러한 회전까지 예측하게끔 만들려면 각각의 회전에 대해서 전부 예측할 수 있도록 모델을 훨씬 더 깊고 복잡하게 쌓아야한다. 매우 비효율적인 일이 아닐 수 없다…
즉 근육을 위해 남성성을 포기한 로이더처럼 invariance함을 얻기위해 나머지 안중요한 정보들을 버림으로써 spatial relationship을 전혀 고려하지 않게 되었다.

2번 째 그림은 사람이 보기에 너무나도 기괴한 이미지임에도 불구하고 CNN은 사람의 얼굴로 정확히 예측할 수 있다. 왜냐하면 얼굴을 구성하는 feature가 image안에 다 들어있기 때문이다. 다시한번 말하자면 CNN의 단점은 translation invariance함을 얻기 위해 정보들을 버려서 spatial relationship을 고려하지 않게 되었다.
그렇다면 Capsule Network는 translation equivariance를 이용해 spatial relationship을 고려한 예측을 한다는것인데 어떤식으로 그게 가능한지는 다음 포스트에서 정리하도록 하겠다.