- Data
- Imbalanced Data Process
- 구현
- GPU
- Data to Torch
- Score 메서드
- Loss Graph
- Model
- SFS
- Trainning
- Model Load
- 결론
Data
지난 NHIS전처리 에 이어서 DNN을 이용한 당뇨환자 예측을 해보았다. 그 전에 데이터에 대해 간략히 요약하면
926582 x 44사이즈의 데이터Target
- 0 : 정상 62%
- 1 : 전당뇨 30%
- 2 : 당뇨 8%
multi class classier 문제이며 imbalanced data 이다.
Imbalanced Data Process
불균형 데이터를 다루기 위해 2가지 전처리를 시행했다.
Data Augumentation
- SMOTE_ENN-Oversampling
- OSS-Undersampling
Class weight
전처리는 오래걸리므로 혹시 쓸사람들을 위해 데이터 를 공유한다.
Class Weight
class weight는 Loss를 구할 때 각 파라미터에 가중치를 줘서 라벨마다 다른 패널티를 줄 수있게 해준다.

$C_i$값이 Cross Entropy에 추가되며 너무 큰 패널티를 주지 않도록 하기 위해 $C_i$에 $q$를 이용해 값의 크기를 조절 해준다.
구현
root 디렉토리 밑에
root_dir/
|---runs/
|---model/
|---data/
| |-y_valid.csv
| |-...
이렇게 폴더를 3개만들어둔다.
runs/ : tensorboard를 위한 폴더
model/ : 모델이 저장될 폴더
data/ : 데이터 폴더
import
# data analysis and wrangling
import math
import pandas as pd
import numpy as np
import random as rnd
import scipy.stats as stats
from scipy.stats.mstats import winsorize
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
# visualization
import missingno as msno
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# ignore warnings
import warnings
warnings.filterwarnings(action='ignore')
# machine learning
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC, LinearSVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import Perceptron
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
Data Load
Original
# Original version
from sklearn.model_selection import train_test_split
df = pd.read_csv('data/out.csv')
y = df['BLDS']
X = df.drop(['BLDS'], axis = 1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42, stratify=y, shuffle = True)
X_valid, X_test, y_valid, y_test = train_test_split(X_test, y_test, test_size=0.5, random_state=42, stratify=y_test, shuffle = True)
Oversampled
# Over Sampling version
X_train = pd.read_csv('data/over_X_train.csv')
y_train = pd.read_csv('data/over_y_train.csv')
X_valid = pd.read_csv('data/X_valid.csv')
y_valid = pd.read_csv('data/y_valid.csv')
X_test = pd.read_csv('data/X_test.csv')
y_test = pd.read_csv('data/y_test.csv')
Undersampled
# Over Sampling version
X_train = pd.read_csv('data/over_X_train.csv')
y_train = pd.read_csv('data/over_y_train.csv')
X_valid = pd.read_csv('data/X_valid.csv')
y_valid = pd.read_csv('data/y_valid.csv')
X_test = pd.read_csv('data/X_test.csv')
y_test = pd.read_csv('data/y_test.csv')
Normalization
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X_train)
X_train_sc = scaler.transform(X_train)
X_valid_sc = scaler.transform(X_valid)
X_test_sc = scaler.transform(X_test)
GPU
print(torch.cuda.is_available())
dev = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
True
Data to Torch
def preprocess(x, y):
return x.to(dev, dtype=torch.float), y.to(dev, dtype=torch.long)
class WrappedDataLoader:
def __init__(self, dl, func):
self.dl = dl
self.func = func
def __len__(self):
return len(self.dl)
def __iter__(self):
batches = iter(self.dl)
for b in batches:
yield (self.func(*b))
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
X_train, y_train, X_valid, y_valid, X_test, y_test = map(
torch.tensor, (np.array(X_train_sc), np.array(y_train), np.array(X_valid_sc), np.array(y_valid), np.array(X_test_sc), np.array(y_test))
)
y_train = y_train.view(-1)
y_valid = y_valid.view(-1)
y_test = y_test.view(-1)
Score 메서드
from sklearn.metrics import make_scorer
from sklearn.metrics import confusion_matrix
variance = lambda score : np.var(score)
def weight_score(matrix) :
normal, pre_diabetes, diabetes = matrix
normal_recall = normal[0] / normal.sum()
pre_diabetes_recall = (pre_diabetes[1]+pre_diabetes[2]*0.3) / pre_diabetes.sum()
diabetes_recall = (diabetes[1]*0.3+diabetes[2]) / diabetes.sum()
return normal_recall, pre_diabetes_recall, diabetes_recall
def custom_recall(y_true, y_pred) :
matrix = confusion_matrix(y_true, y_pred)
normal_recall, pre_diabetes_recall, diabetes_recall = weight_score(matrix)
return (normal_recall+ pre_diabetes_recall+ diabetes_recall) / 3
from sklearn.metrics import confusion_matrix
def print_score(y_test, y_pred) :
confusion = confusion_matrix(y_test, y_pred, labels=None)
#importing accuracy_score, precision_score, recall_score, f1_score
normal_recall, pre_diabetes_recall, diabetes_recall = weight_score(confusion)
print('custom normal Recall :', normal_recall)
print('custom pre diabetes Recall :', pre_diabetes_recall)
print('custom pre diabetes Recall :', diabetes_recall)
print('')
print('avg Recall : {}'.format(custom_recall(y_test, y_pred)))
print('val Recall : {}'.format(variance([normal_recall, pre_diabetes_recall, diabetes_recall])))
normal, pre, diabet = confusion
print('ratio cunfsion matrix')
print('[1.00 : {:.2f} : {:.2f}]'.format(normal[1] / normal[0], normal[2] / normal[0]))
print('[{:.2f} : 1.00 : {:.2f}]'.format(pre[0] / pre[1], pre[2] / pre[1]))
print('[{:.2f} : {:.2f} : 1.00]'.format(diabet[0] / diabet[2], diabet[1] / diabet[2]))
def accuracy(data):
model.eval()
y_pred = []
y_true = []
with torch.no_grad():
for xb, yb in notebook.tqdm(data) :
output = model(xb)
pred = torch.argmax(output, dim = 1)
y_pred += pred.tolist()
y_true += yb.tolist()
print_score(y_true, y_pred)
def predict(data, model):
model.eval()
y_pred = []
y_true = []
with torch.no_grad():
for xb, yb in data :
output = model(xb)
pred = torch.argmax(output, dim = 1)
y_pred += pred.tolist()
y_true += yb.tolist()
return custom_recall(y_true, y_pred)
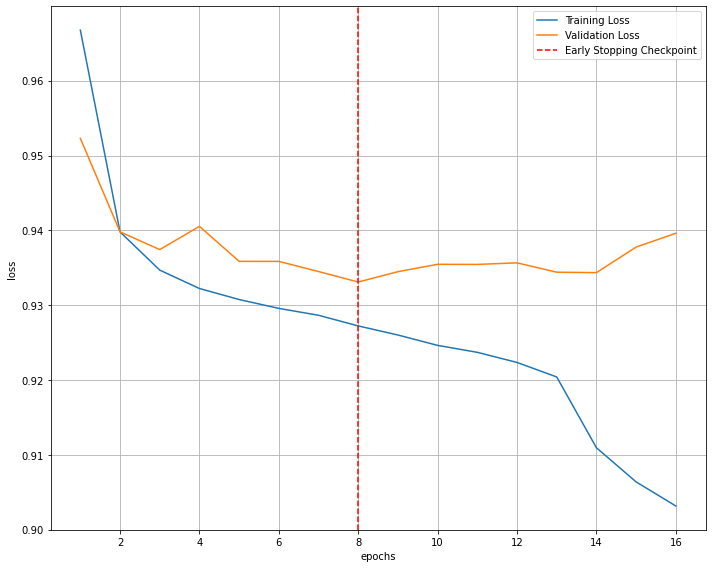
Loss Graph
def loss_graph(train_loss, valid_loss) :
# 훈련이 진행되는 과정에 따라 loss를 시각화
fig = plt.figure(figsize=(10,8))
plt.plot(range(1,len(train_loss)+1),train_loss, label='Training Loss')
plt.plot(range(1,len(valid_loss)+1),valid_loss,label='Validation Loss')
# validation loss의 최저값 지점을 찾기
minposs = valid_loss.index(min(valid_loss))+1
plt.axvline(minposs, linestyle='--', color='r',label='Early Stopping Checkpoint')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
fig.savefig('model'+path+'-loss_plot.png', bbox_inches = 'tight')
print('lr : {}, keep_prob : {}, weight_decay : {}, layer : {}'.format(lr, keep_prob, weight_decay, layer))
print('==='*30)
print('==='*30)
Model
def fc_layer(size_in, size_out, keep_prob, xavier=True):
linear = nn.Linear(size_in, size_out)
if xavier :
torch.nn.init.xavier_uniform_(linear.weight)
layer = nn.Sequential(
linear,
nn.BatchNorm1d(size_out),
nn.Tanh(),
nn.Dropout(p = 1 - keep_prob)
)
return layer
class MyModule(nn.Module):
def __init__(self, input_ = 48, layer = [10], keep_prob = 1, xavier = True):
super().__init__()
self.log_softmax = nn.LogSoftmax()
self.linears = nn.ModuleList()
self.input = input_
for output in layer :
self.linears.append(fc_layer(self.input, output, keep_prob, xavier))
self.input = output
self.linears.append(fc_layer(self.input, 3, keep_prob, xavier))
def forward(self, x):
for linear in self.linears :
# apply dropout
x = linear(x)
# output layer
x = self.log_softmax(x)
return x
EarlyStopping
class EarlyStopping:
"""주어진 patience 이후로 validation loss가 개선되지 않으면 학습을 조기 중지"""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
"""
Args:
patience (int): validation loss가 개선된 후 기다리는 기간
Default: 7
verbose (bool): True일 경우 각 validation loss의 개선 사항 메세지 출력
Default: False
delta (float): 개선되었다고 인정되는 monitered quantity의 최소 변화
Default: 0
path (str): checkpoint저장 경로
Default: 'checkpoint.pt'
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''validation loss가 감소하면 모델을 저장한다.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), './model/'+self.path)
self.val_loss_min = val_loss
Train method
# model, optim 설정
def get_model(input_ = 34, lr = 0.01, keep_prob = 0.5, xavier = True, weight_decay = 0.005, layer = [10]):
model = MyModule(input_ = input_, layer = layer, keep_prob = keep_prob, xavier = xavier)
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay = weight_decay)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience = 4)
return model.to(dev), optimizer, scheduler
def loss_batch(model, loss_func, xb, yb, opt=None):
out = []
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
out.append(opt.param_groups[0]['lr'])
out.append(loss.item())
return out
def fit(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path):
start = time.time()
train_loss, valid_loss = [], []
early_stopping = EarlyStopping(patience = 8, verbose = True, delta=0.0001, path = path+'_checkpoint.pt')
for epoch in notebook.tqdm(range(epochs), desc = 'Epoch'):
print('[Epoch: %d]' % (epoch))
model.train()
loss = []
for xb, yb in notebook.tqdm(train_dl, desc = 'train'):
lr, l = loss_batch(model, loss_func, xb, yb, opt)
loss.append(l)
avg_loss = sum(loss) / len(loss)
print("train avg_loss: %f" % (avg_loss))
train_loss.append(avg_loss)
model.eval()
loss = []
y_pred = []
y_true = []
with torch.no_grad() :
for xb, yb in valid_dl :
l = loss_batch(model, loss_func, xb, yb)[0]
loss.append(l)
output = model(xb)
pred = torch.argmax(output, dim = 1)
y_pred += pred.tolist()
y_true += yb.tolist()
avg_loss = sum(loss) / len(loss)
print("valid avg_loss: %f" % (avg_loss))
valid_loss.append(avg_loss)
recall = custom_recall(y_true, y_pred)
print('valid recall : ', recall)
writer.add_scalar('{}/Loss/recall'.format(path), recall, epoch)
scheduler.step(avg_loss)
early_stopping(avg_loss, model)
print('-'*50)
if early_stopping.early_stop:
print("Early stopping")
break
print("cost time :", time.time() - start)
writer.flush()
writer.close()
model.load_state_dict(torch.load('model/'+path+'_checkpoint.pt'))
return model, train_loss, valid_loss
SFS
Sequential Feature Selection은 아쉽게도 Pytorch 로 구현이 되어있지 않아서 직접 구현해야했다.
Algorithm

Code
def fit_(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path):
early_stopping = EarlyStopping(patience = 8, verbose = False, delta=0.0001, path = path+'_checkpoint.pt')
for epoch in range(epochs):
model.train()
loss = []
for xb, yb in train_dl:
lr, l = loss_batch(model, loss_func, xb, yb, opt)
loss.append(l)
avg_loss = sum(loss) / len(loss)
model.eval()
loss = []
with torch.no_grad() :
for xb, yb in valid_dl :
l = loss_batch(model, loss_func, xb, yb)[0]
loss.append(l)
avg_loss = sum(loss) / len(loss)
scheduler.step(avg_loss)
early_stopping(avg_loss, model)
if early_stopping.early_stop:
#print("Early stopping")
break
model.load_state_dict(torch.load('model/'+path+'_checkpoint.pt'))
return model
def SFS(batch_size, epoch, lr, keep_prob, xavier, weight_decay, layer, weight) :
full_set = set(x for x in range(48))
sub_sets = [set() for _ in range(49)]
scores = [0]*49
best_score = 0
best_combination = []
for k in notebook.tqdm(range(len(full_set)), desc = 'n_features') :
score = 0
combination = []
for feature_idx in notebook.tqdm(full_set, desc = '{} feature'.format(k+1)):
selected = list(sub_sets[k]) + [feature_idx]
X_train_sub = X_train_sc[:, selected]
X_valid_sub = X_valid[:, selected]
train_ds = TensorDataset(X_train_sub, y_train)
valid_ds = TensorDataset(X_valid_sub, y_valid)
train_dl, valid_dl = get_data(train_ds, valid_ds, batch_size)
train_dl = WrappedDataLoader(train_dl, preprocess)
valid_dl = WrappedDataLoader(valid_dl, preprocess)
input_ = k+1
#weights = torch.tensor([0.5, 1.4, 5], dtype=torch.float32, device = dev)
loss_func = nn.CrossEntropyLoss(weight = weight)
model, opt, scheduler = get_model(input_ = input_, lr = lr, keep_prob = keep_prob, xavier = xavier, weight_decay = weight_decay, layer = layer)
model = fit_(epoch, model, loss_func, opt, scheduler, train_dl, valid_dl, path = '')
tmp = predict(valid_dl, model)
if score < tmp :
score = tmp
combination = selected
torch.cuda.empty_cache()
print('{} num combination done'.format(k+1))
print('{} num best combination is {}, score is {}'.format(k+1, combination, round(score, 2)))
sub_sets[k+1] = set(combination)
scores[k+1] = score
full_set -= sub_sets[k+1]
if best_score < score :
best_score = score
best_combination = combination
print('best combinations is ', best_combination)
print('score is : ', best_score)
return sub_sets, scores
Trainning
Trainning은 총 4단계로 구분했다.
- Default Parameter
- Class Weight 적용
- SFS 적용
- Hyper parameter Tunning
batch_size = 4096
train_ds = TensorDataset(X_train, y_train)
valid_ds = TensorDataset(X_valid, y_valid)
train_dl, valid_dl = get_data(train_ds, valid_ds, batch_size)
train_dl = WrappedDataLoader(train_dl, preprocess)
valid_dl = WrappedDataLoader(valid_dl, preprocess)
Default Parameter
# Hyper parameters
epochs = 100
lr = 0.005
xavier = True
## penalty
keep_prob = 1 # 0 ~ 1 사이 값, 낮을 수록 강한 패널티
weight_decay = 0 # 0 이상 값, 높을 수록 강한 패널티
# layer shape
layer = [512]
loss_func = nn.CrossEntropyLoss()
path = 'HyperParams-{}_{}_{}_{}'.format(lr, keep_prob, weight_decay, layer)
model, opt, scheduler = get_model(input_ = 48, lr = lr, keep_prob = keep_prob, xavier = xavier, weight_decay = weight_decay, layer = layer)
model, train_loss, valid_loss = fit(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path = path)
loss_graph(train_loss, valid_loss)
accuracy(valid_dl)
torch.cuda.empty_cache()
print('='*50)
...
[Epoch: 0]
train avg_loss: 0.894963
valid avg_loss: 0.835324
valid recall : 0.5412405559012073
Validation loss decreased (inf --> 0.835324). Saving model ...
--------------------------------------------------
[Epoch: 1]
train avg_loss: 0.823006
valid avg_loss: 0.816862
valid recall : 0.5409689107452479
Validation loss decreased (0.835324 --> 0.816862). Saving model ...
--------------------------------------------------
...
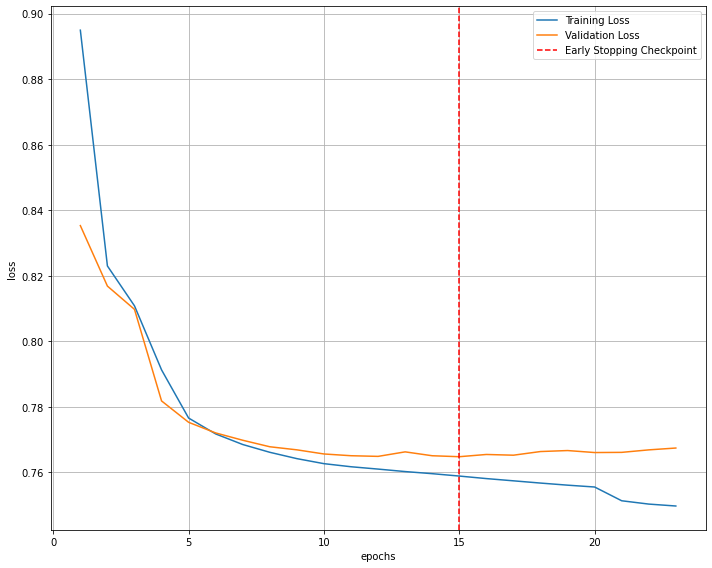
lr : 0.005, keep_prob : 1, weight_decay : 0, layer : [512]
==========================================================================================
==========================================================================================
custom normal Recall : 0.9119609117305937
custom pre diabetes Recall : 0.15041737179365292
custom pre diabetes Recall : 0.23776223776223776
custom Recall : 0.55
ratio cunfsion matrix
[1.00 : 0.05 : 0.04]
[6.18 : 1.00 : 0.53]
[3.64 : 1.64 : 1.00]
==================================================
Class Weight
# Hyper parameters
epochs = 100
lr = 0.005
xavier = True
## penalty
keep_prob = 1 # 0 ~ 1 사이 값, 낮을 수록 강한 패널티
weight_decay = 0 # 0 이상 값, 높을 수록 강한 패널티
q = 0.001
# layer shape
layer = [512]
# Cross entropy loss func
from itertools import product
rang = range(1, 10)
for c1, c2, c3 in product(rang, rang, rang) :
class_weight = [c1, c2, c3]
weight = torch.tensor(class_weight, dtype=torch.float32, device = dev)
loss_func = nn.CrossEntropyLoss(weight = weight*q)
path = 'HyperParams-{}_{}_{}_{}'.format(lr, keep_prob, weight_decay, layer)
model, opt, scheduler = get_model(input_ = 48, lr = lr, keep_prob = keep_prob, xavier = xavier, weight_decay = weight_decay, layer = layer)
model, train_loss, valid_loss = fit(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path = path)
loss_graph(train_loss, valid_loss)
accuracy(valid_dl)
torch.cuda.empty_cache()
print('='*50)
가장 Best였던 Class weight의 비율을 찾아주어야한다.
[Epoch: 0]
train avg_loss: 0.977940
valid avg_loss: 0.952785
valid recall : 0.5715820235101884
Validation loss decreased (inf --> 0.952785). Saving model ...
--------------------------------------------------
[Epoch: 1]
train avg_loss: 0.945513
valid avg_loss: 0.943527
valid recall : 0.5742685593794018
Validation loss decreased (0.952785 --> 0.943527). Saving model ...
--------------------------------------------------
...
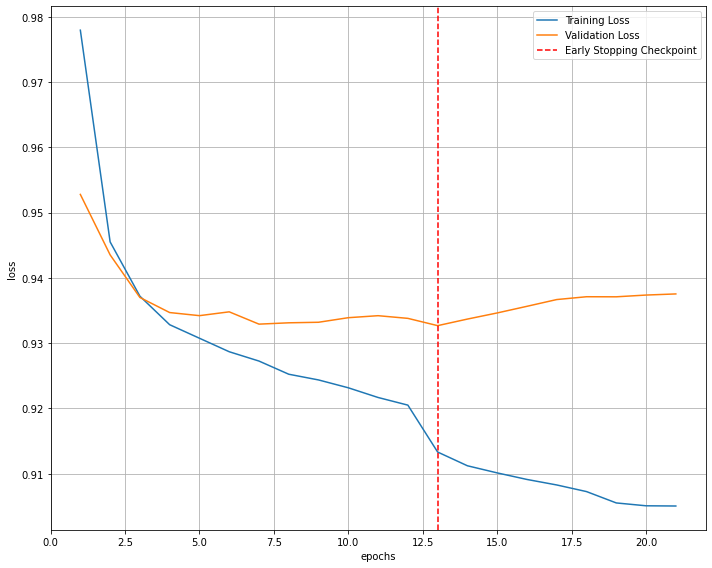
lr : 0.005, keep_prob : 1, weight_decay : 0, layer : [512]
==========================================================================================
==========================================================================================
custom normal Recall : 0.564937361706328
custom pre diabetes Recall : 0.6011028502975794
custom pre diabetes Recall : 0.58076026537565
custom Recall : 0.58
ratio cunfsion matrix
[1.00 : 0.64 : 0.13]
[0.52 : 1.00 : 0.29]
[0.22 : 1.04 : 1.00]
==================================================
SFS
# Cross entropy loss func
class_weight = [1, 3, 7]
weight = torch.tensor(class_weight, dtype=torch.float32, device = dev)
# Hyper parameters
epochs = 100
lr = 0.005
xavier = True
## penalty
keep_prob = 1 # 0 ~ 1 사이 값, 낮을 수록 강한 패널티
weight_decay = 0 # 0 이상 값, 높을 수록 강한 패널티
q = 0.01
# layer shape
layer = [512]
sub_sets, scores = SFS(batch_size, 500, lr, keep_prob, xavier, weight_decay, layer, weight*q)
1 num combination done
1 num best combination is [43], score is 0.52
2 num combination done
2 num best combination is [43, 36], score is 0.52
3 num combination done
3 num best combination is [43, 36, 28], score is 0.52
4 num combination done
4 num best combination is [43, 36, 28, 13], score is 0.52
5 num combination done
5 num best combination is [13, 43, 36, 28, 23], score is 0.52
6 num combination done
6 num best combination is [36, 43, 13, 23, 28, 33], score is 0.52
7 num combination done
7 num best combination is [33, 36, 43, 13, 23, 28, 0], score is 0.53
8 num combination done
8 num best combination is [0, 33, 36, 43, 13, 23, 28, 17], score is 0.54
9 num combination done
9 num best combination is [0, 33, 36, 43, 13, 17, 23, 28, 11], score is 0.56
10 num combination done
10 num best combination is [0, 33, 36, 43, 11, 13, 17, 23, 28, 6], score is 0.56
11 num combination done
11 num best combination is [0, 33, 36, 6, 43, 11, 13, 17, 23, 28, 3], score is 0.57
12 num combination done
12 num best combination is [0, 33, 3, 36, 6, 43, 11, 13, 17, 23, 28, 15], score is 0.57
13 num combination done
13 num best combination is [0, 33, 3, 36, 6, 43, 11, 13, 15, 17, 23, 28, 16], score is 0.57
14 num combination done
14 num best combination is [0, 33, 3, 36, 6, 43, 11, 13, 15, 16, 17, 23, 28, 14], score is 0.58
15 num combination done
15 num best combination is [0, 33, 3, 36, 6, 43, 11, 13, 14, 15, 16, 17, 23, 28, 8], score is 0.57
16 num combination done
16 num best combination is [0, 33, 3, 36, 6, 8, 43, 11, 13, 14, 15, 16, 17, 23, 28, 9], score is 0.58
17 num combination done
17 num best combination is [0, 33, 3, 36, 6, 8, 9, 43, 11, 13, 14, 15, 16, 17, 23, 28, 18], score is 0.58
18 num combination done
18 num best combination is [0, 33, 3, 36, 6, 8, 9, 43, 11, 13, 14, 15, 16, 17, 18, 23, 28, 38], score is 0.58
19 num combination done
19 num best combination is [0, 33, 3, 36, 6, 38, 8, 9, 43, 11, 13, 14, 15, 16, 17, 18, 23, 28, 47], score is 0.58
20 num combination done
20 num best combination is [0, 3, 6, 8, 9, 11, 13, 14, 15, 16, 17, 18, 23, 28, 33, 36, 38, 43, 47, 2], score is 0.58
21 num combination done
21 num best combination is [0, 2, 3, 6, 8, 9, 11, 13, 14, 15, 16, 17, 18, 23, 28, 33, 36, 38, 43, 47, 40], score is 0.58
22 num combination done
22 num best combination is [0, 2, 3, 6, 8, 9, 11, 13, 14, 15, 16, 17, 18, 23, 28, 33, 36, 38, 40, 43, 47, 30], score is 0.58
23 num combination done
23 num best combination is [0, 2, 3, 6, 8, 9, 11, 13, 14, 15, 16, 17, 18, 23, 28, 30, 33, 36, 38, 40, 43, 47, 10], score is 0.58
24 num combination done
24 num best combination is [0, 2, 3, 6, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 28, 30, 33, 36, 38, 40, 43, 47, 5], score is 0.58
25 num combination done
25 num best combination is [0, 2, 3, 5, 6, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 28, 30, 33, 36, 38, 40, 43, 47, 7], score is 0.58
26 num combination done
26 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 28, 30, 33, 36, 38, 40, 43, 47, 39], score is 0.58
27 num combination done
27 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 28, 30, 33, 36, 38, 39, 40, 43, 47, 26], score is 0.58
28 num combination done
28 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 26, 28, 30, 33, 36, 38, 39, 40, 43, 47, 34], score is 0.58
29 num combination done
29 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 26, 28, 30, 33, 34, 36, 38, 39, 40, 43, 47, 31], score is 0.58
30 num combination done
30 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 26, 28, 30, 31, 33, 34, 36, 38, 39, 40, 43, 47, 45], score is 0.58
31 num combination done
31 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 26, 28, 30, 31, 33, 34, 36, 38, 39, 40, 43, 45, 47, 12], score is 0.58
32 num combination done
32 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 23, 26, 28, 30, 31, 33, 34, 36, 38, 39, 40, 43, 45, 47, 20], score is 0.58
33 num combination done
33 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 23, 26, 28, 30, 31, 33, 34, 36, 38, 39, 40, 43, 45, 47, 21], score is 0.58
34 num combination done
34 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 26, 28, 30, 31, 33, 34, 36, 38, 39, 40, 43, 45, 47, 37], score is 0.58
35 num combination done
35 num best combination is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 26, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 47, 4], score is 0.58
36 num combination done
36 num best combination is [0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 26, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 47, 25], score is 0.58
37 num combination done
37 num best combination is [0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 25, 26, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 47, 46], score is 0.58
38 num combination done
38 num best combination is [0, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 25, 26, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 46, 47, 1], score is 0.58
39 num combination done
39 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 25, 26, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 46, 47, 24], score is 0.58
40 num combination done
40 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 24, 25, 26, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 46, 47, 27], score is 0.58
41 num combination done
41 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 24, 25, 26, 27, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 45, 46, 47, 44], score is 0.58
42 num combination done
42 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 24, 25, 26, 27, 28, 30, 31, 33, 34, 36, 37, 38, 39, 40, 43, 44, 45, 46, 47, 35], score is 0.58
43 num combination done
43 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 21, 23, 24, 25, 26, 27, 28, 30, 31, 33, 34, 35, 36, 37, 38, 39, 40, 43, 44, 45, 46, 47, 19], score is 0.57
44 num combination done
44 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 23, 24, 25, 26, 27, 28, 30, 31, 33, 34, 35, 36, 37, 38, 39, 40, 43, 44, 45, 46, 47, 42], score is 0.58
45 num combination done
45 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 23, 24, 25, 26, 27, 28, 30, 31, 33, 34, 35, 36, 37, 38, 39, 40, 42, 43, 44, 45, 46, 47, 22], score is 0.58
46 num combination done
46 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 30, 31, 33, 34, 35, 36, 37, 38, 39, 40, 42, 43, 44, 45, 46, 47, 32], score is 0.57
47 num combination done
47 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 42, 43, 44, 45, 46, 47, 29], score is 0.57
48 num combination done
48 num best combination is [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 42, 43, 44, 45, 46, 47, 41], score is 0.57
best combinations is [0, 2, 3, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 23, 26, 28, 30, 31, 33, 34, 36, 38, 39, 40, 43, 47, 45]
score is : 0.5794059581240972
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 10))
plt.plot([str(x+1) for x in range(len(scores[1:]))], scores[1:], label="score")
plt.plot()
plt.xlabel("num features")
plt.ylabel("recall score")
plt.title("SFS score")
plt.show()
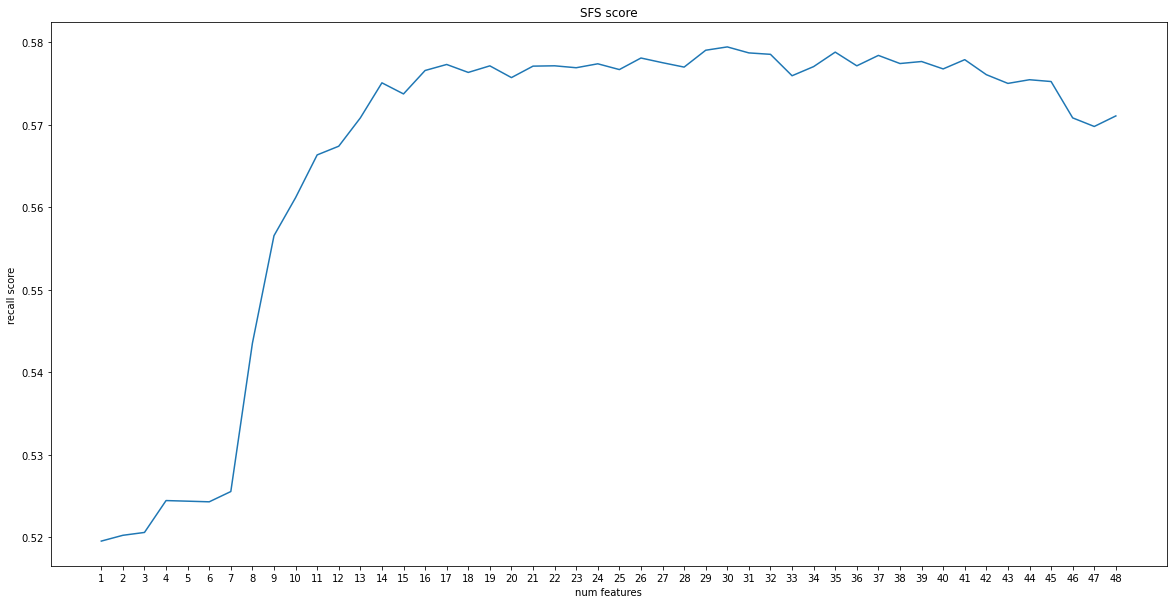
idx = scores.index(max(scores[20:]))
selected = list(sub_sets[idx])
print('selected features is {} features\n{}'.format(len(selected), [df.columns[i] for i in selected]))
print('not selected feature is\n', [df.columns[i] for i in range(48) if i not in selected])
print('score is ', scores[idx])
selected features is 30 features
['AGE_GROUP', 'WEIGHT', 'WAIST', 'SIGHT_RIGHT', 'BP_HIGH', 'BP_LWST', 'BLDS', 'TOT_CHOLE', 'TRIGLYCERIDE', 'HDL_CHOLE', 'HMG', 'OLIG_PROTE_CD', 'CREATININE', 'SGOT_AST', 'SGPT_ALT', 'GAMMA_GTP', 'SIDO_DAJEON', 'SIDO_GB', 'SIDO_GYEONGGI', 'SIDO_JB', 'SIDO_JN', 'SIDO_SEJONG', 'SIDO_SEOUL', 'HEAR_LEFT_Normal', 'SMK_STAT_TYPE_CD_Yes', 'DRK_YN_Yes', 'BMI', 'BP_LWST_level', 'GAMMA_GTP_level', 'HTGW']
not selected feature is
['HEIGHT', 'SIGHT_LEFT', 'LDL_CHOLE', 'SEX_male', 'SIDO_CB', 'SIDO_CN', 'SIDO_DAGU', 'SIDO_FOREIGN', 'SIDO_GANGWON', 'SIDO_GN', 'SIDO_INCHEON', 'SIDO_KWANGJU', 'SIDO_ULSAN', 'HEAR_RIGHT_Normal', 'PIBW', 'BP_HIGH_level', 'ABD_FAT', 'WHtR']
score is 0.5794059581240972
batch_size = 4096
X_train_sfs = X_train[:, selected]
X_valid_sfs = X_valid[:, selected]
X_test_sfs = X_test[:, selected]
train_ds = TensorDataset(X_train_sfs, y_train)
valid_ds = TensorDataset(X_valid_sfs, y_valid)
test_ds = TensorDataset(X_test_sfs, y_test)
train_dl, valid_dl = get_data(train_ds, valid_ds, batch_size)
test_dl = DataLoader(test_ds, batch_size=batch_size * 2)
train_dl = WrappedDataLoader(train_dl, preprocess)
valid_dl = WrappedDataLoader(valid_dl, preprocess)
test_dl = WrappedDataLoader(test_dl, preprocess)
# Cross entropy loss func
# Hyper parameters
epochs = 100
lr = 0.005
xavier = True
## penalty
keep_prob = 1 # 0 ~ 1 사이 값, 낮을 수록 강한 패널티
weight_decay = 0 # 0 이상 값, 높을 수록 강한 패널티
q = 0.001
# layer shape
layer =[512]
class_weight = [1, 3, 7]
weight = torch.tensor(class_weight, dtype=torch.float32, device = dev)
loss_func = nn.CrossEntropyLoss(weight = weight*q)
path = 'HyperParams-{}_{}_{}_{}'.format(lr, keep_prob, weight_decay, layer)
model, opt, scheduler = get_model(input_ = 26, lr = lr, keep_prob = keep_prob, xavier = xavier, weight_decay = weight_decay, layer = layer)
model, train_loss, valid_loss = fit(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path = path)
loss_graph(train_loss, valid_loss)
print(class_weight)
accuracy(valid_dl)
torch.cuda.empty_cache()
print('='*50)
[Epoch: 0]
train avg_loss: 0.926910
valid avg_loss: 1.027874
valid recall : 0.5732494134958254
Validation loss decreased (inf --> 1.027874). Saving model ...
--------------------------------------------------
[Epoch: 1]
train avg_loss: 0.892531
valid avg_loss: 0.991195
valid recall : 0.5709796481657282
Validation loss decreased (1.027874 --> 0.991195). Saving model ...
--------------------------------------------------
...
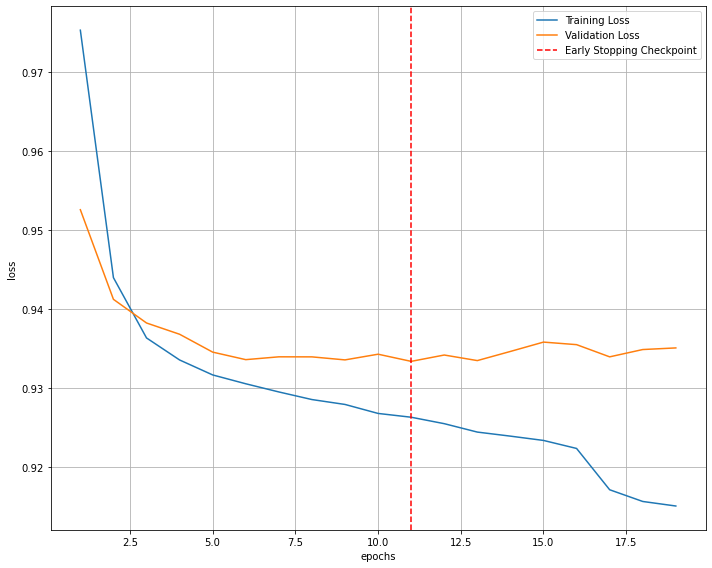
lr : 0.005, keep_prob : 1, weight_decay : 0, layer : [512]
==========================================================================================
==========================================================================================
custom normal Recall : 0.5786741903908005
custom pre diabetes Recall : 0.5823133089102133
custom pre diabetes Recall : 0.6212240750702289
custom Recall : 0.59
ratio cunfsion matrix
[1.00 : 0.59 : 0.14]
[0.55 : 1.00 : 0.34]
[0.18 : 0.83 : 1.00]
custom normal Recall : 0.5732863923139565
custom pre diabetes Recall : 0.5789926032971421
custom pre diabetes Recall : 0.602868925945849
custom Recall : 0.58
ratio cunfsion matrix
[1.00 : 0.60 : 0.14]
[0.56 : 1.00 : 0.34]
[0.21 : 0.89 : 1.00]
==================================================
Hyper Parameter Running
각 파라미터를 튜닝하며 가장 Best였던 값을 keep하며 튜닝했다.
# Cross entropy loss func
# Hyper parameters
epochs = 100
lr = 0.01
xavier = True
## penalty
keep_prob = 1 # 0 ~ 1 사이 값, 낮을 수록 강한 패널티
weight_decay = 0 # 0 이상 값, 높을 수록 강한 패널티
q = 0.1
# layer shape
layer =[2048, 2048, 1024, 512, 256, 128, 64]
weight = torch.tensor(class_weight, dtype=torch.float32, device = dev)
Model Load
model_name = 'model/HyperParams-0.01_1_0_[2048, 2048, 1024, 512, 256, 128, 64]_checkpoint.pt'
model.load_state_dict(torch.load(model_name))
<All keys matched successfully>
accuracy(valid_dl)
custom normal Recall : 0.584086665405401
custom pre diabetes Recall : 0.5771158563252268
custom pre diabetes Recall : 0.5850277927201004
avg Recall : 0.5820767714835761
recall variance : 1.2452959707915428e-05
ratio cunfsion matrix
[1.00 : 0.58 : 0.13]
[0.58 : 1.00 : 0.32]
[0.24 : 0.96 : 1.00]
accuracy(test_dl)
custom normal Recall : 0.5886354475985227
custom pre diabetes Recall : 0.5761047307575297
custom pre diabetes Recall : 0.5952931683700914
avg Recall : 0.5866777822420479
recall variance : 6.328224982583304e-05
ratio cunfsion matrix
[1.00 : 0.57 : 0.13]
[0.58 : 1.00 : 0.33]
[0.22 : 0.93 : 1.00]
결론
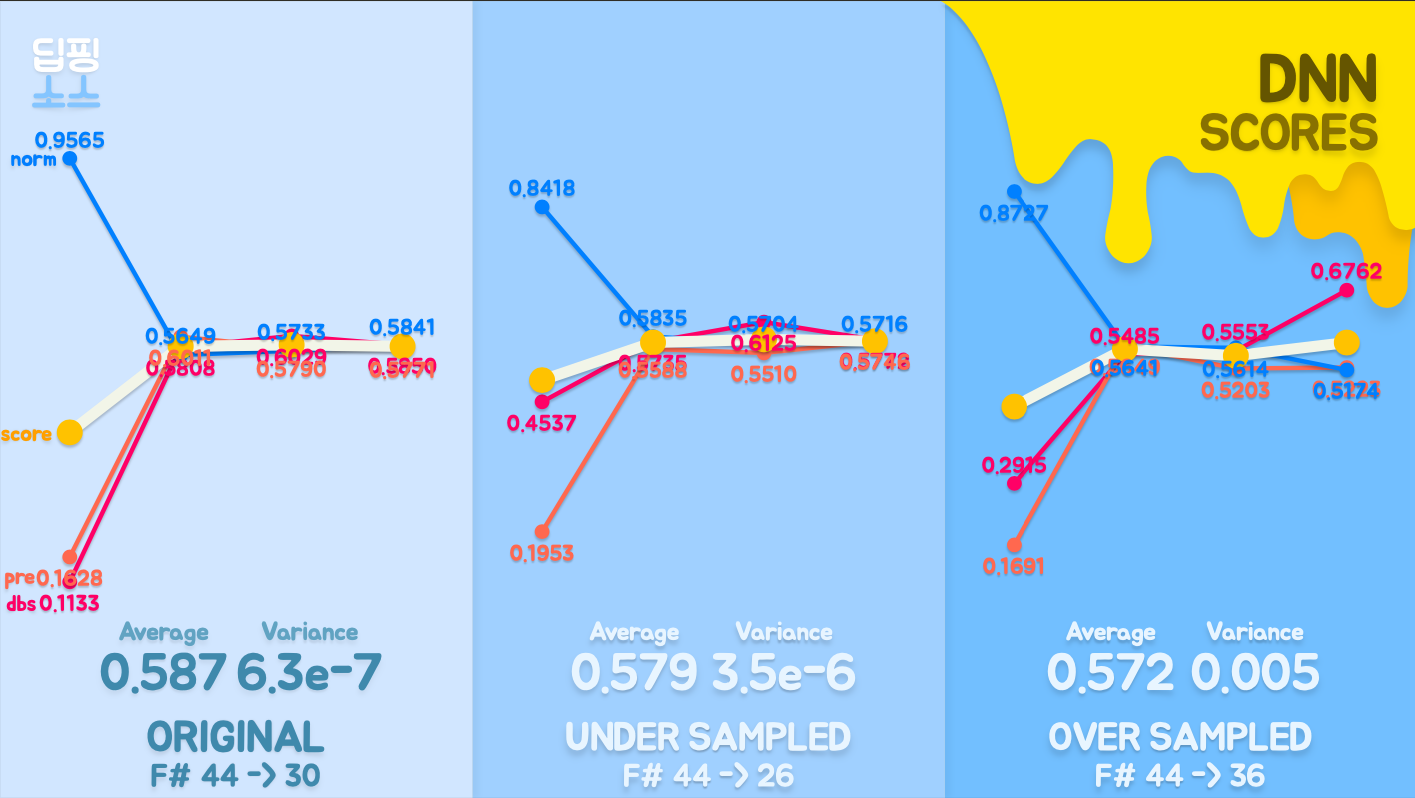
Original 성적이 가장 좋고 Augumentation을 적용한 데이터는 성능이 그렇게 좋지 못했다. 그 이유를 생각해보니 정규화 패널티가 너무 많이 적용되었다는것을 알 수 있었다.
- Data Augumentation
- Class weight
- Dropout
- L2 penalty(weight decay)
4개의 정규화를 한번에 넣으니 학습자체가 아예 되지않아서 성능이 오히려 떨어지는 현상을 이번에 알게되었다. 몸에 좋다고 아무거다 다먹으면 안되듯이 정규화를 막 가져다 쓴다고 좋지는 않았다.