Haribo Blog
알고리즘, 문제풀이, ML, AI-
개빡치는 정밀도 줄이기 & LoRA
 검은 영역 생성하는 모델 학습에서 train 환경
검은 영역 생성하는 모델 학습에서 train 환경 bfloat16에서는 문제없던게 테스트환경fp8로 생성하니 테두리 부분이 개박살나는 현상. 이건 아직도 해결방법 못찾음ㅅㅂ (거의 한달넘게 실험바꿔가며 헉습/실험 했는데 해결 못함ㅋ).- 근데 원인은 몰라도 우회할 방법을 고안해 냈는데 이직을 하게되어 가설이 맞는지는 당분간 확인을 할 수 없게 되었음…
이게 아무래도 높은 precision에서 낮은 precision으로 내려가면서 발생하는 문제가 확실해 보이는데, 근데 하필이면 딱 경계면에 저렇게 폭격이 가해지는 원인이 뭘까?
이걸 파악하기 위해서는 precision 낮추는 과정을 좀 low-level 에서 파악할 필요성이 느껴진다.
-
Optimizer 반파시키기
아래의 그래프들은 LoRA 학습할 때 내가 겪은 다양한 Prodigy Optimizer의 lr 스케줄링 변화 그래프다.
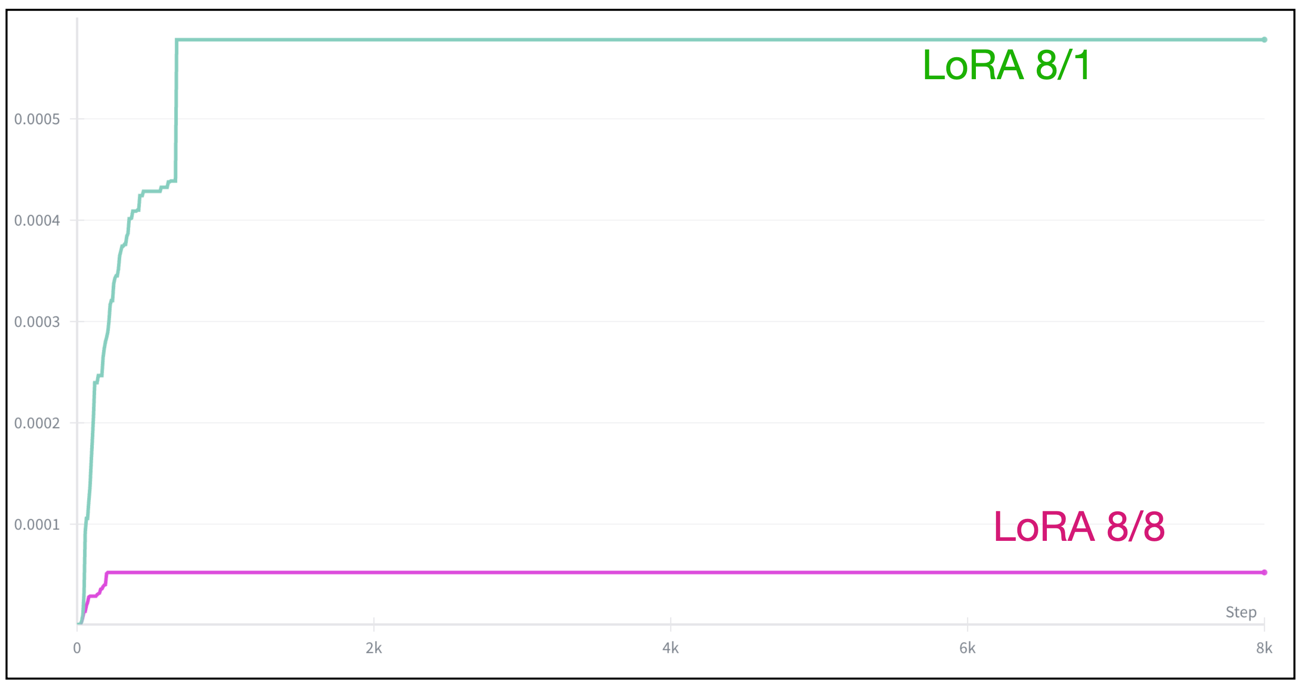

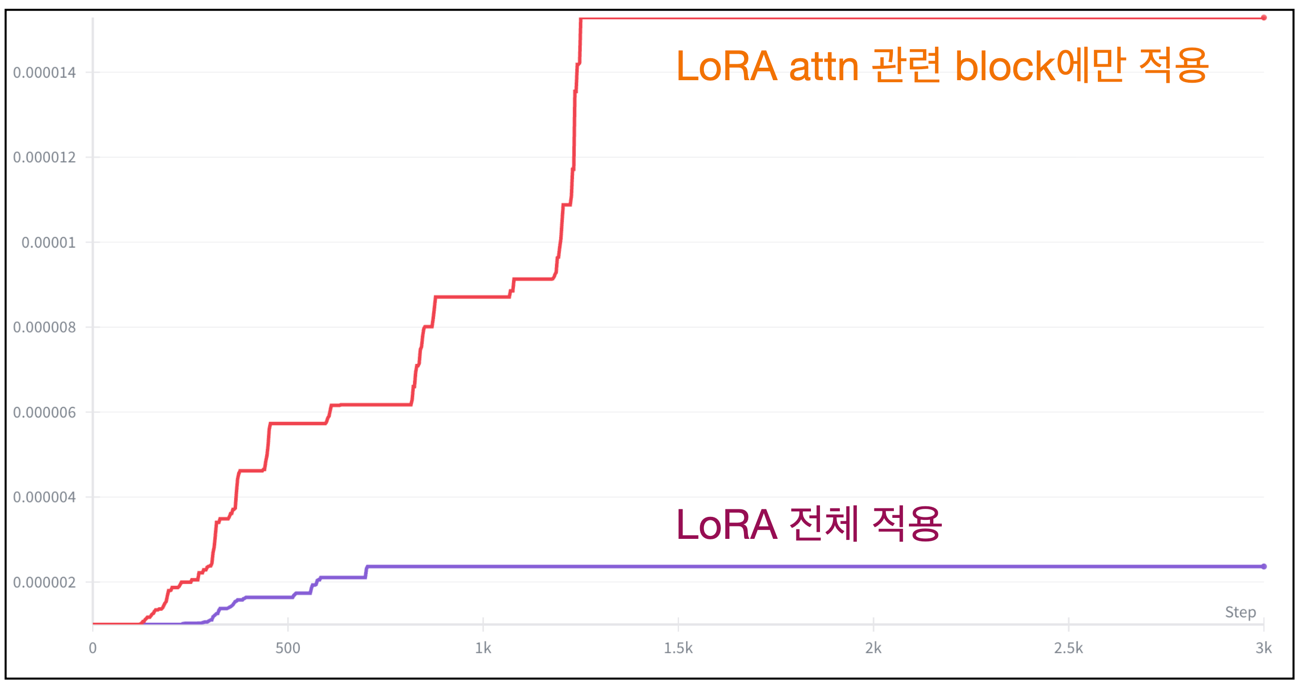
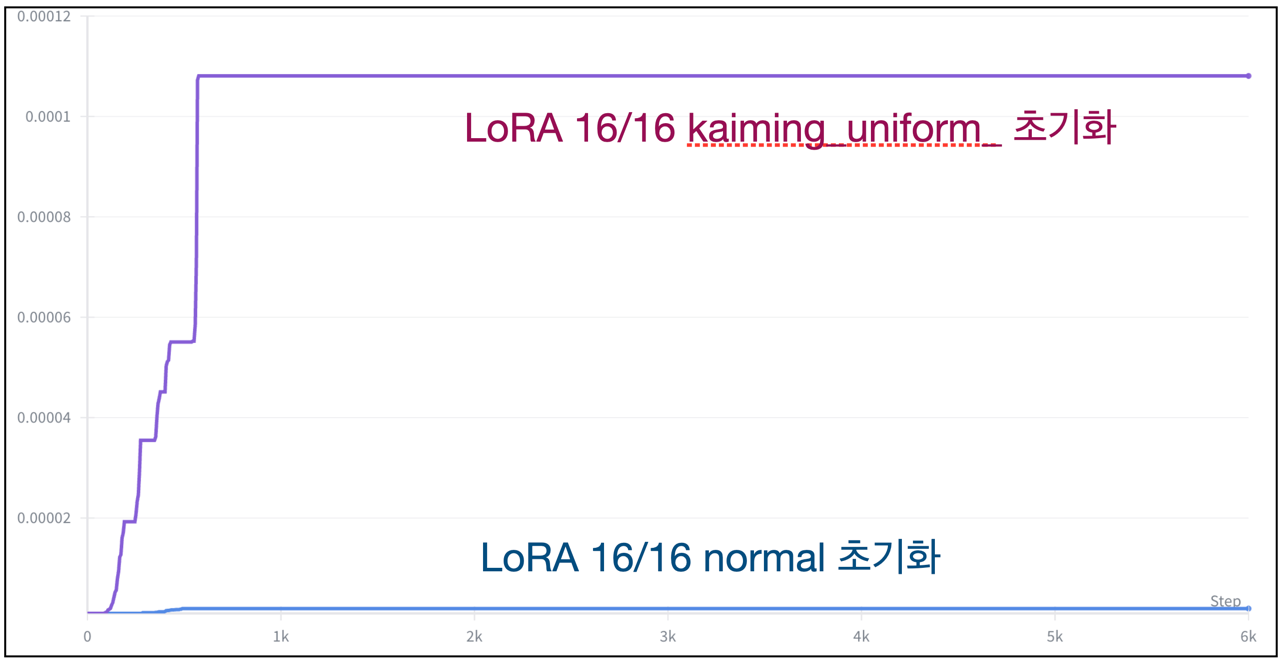
-
여러 Norm들 + Modulation 연산
Norm
FLUX, QWEN-IMAGE 모듈 중 norm을 알아보자.
- (내가아는 오픈소스중 2황이기 때문에…)
API FLUX QWEN-IMAGE VAE Group Norm RMSNorm LDM LayerNorm, RMSNorm RMSNorm, AdaLayerNorm(?) RMSNorm이놈이 챔피언인거같은데, 파보기 전에 틀딱 Norm들 먼저 리마인드 하고 가야겠음.
-
Accelerater 참수 (3편, 각종 함수들)
koyha-ss 가 쓴 다양한 accelerate 실전 코드를 살펴본다.
1. accelerate 세팅
acclerate config나accelerate 플래그로 쓰기 쫌 복잡한애들을 코드로 세팅한다.
공부하고 나니까 코드가 읽힌다.
-
Accelerater 테이크 다운 (2편, 분산학습)
분산학습이 도대체 뭔지 아직도 사실 잘 모른다. GPU 여러개에 모델 복사해 놓고 backprop 할 때 gradiend만 취합해서 보내는건지, GPU 여러개를 하나처럼 쓰는건지, 어떻게 쓰는건지 등등.
이참에 확실히 정리할 예정.분산 학습
구분 개념 Single GPU 한 GPU로 학습 Data Parallel (데이터 병렬) 모델 복사 N개 → 각 GPU가 다른 미니배치 학습 Model Parallel (모델 병렬) 모델 자체를 여러 GPU에 나눠서 저장 Pipeline Parallel 모델을 여러 파트로 나누고 파이프라인처럼 순차 실행 Tensor Parallel 한 레이어 내부 연산을 여러 GPU가 나눠 처리 Multi-Node (분산 학습) GPU 여러 개가 여러 서버(노드) 에 흩어져 있음 FSDP / ZeRO (DeepSpeed) 모델, 그래디언트, 옵티마이저를 GPU 간 분할 저장 Hybrid Parallel 위 병렬 방식을 혼합
-
Accelerater 풀 스파링 (1편, 세팅 및 학습 가속)
내가 정말 리스펙 하면서 쥐어 패고싶은 koyha-ss 코드를 공부하며 알게된 하드웨어 가속기 Accelerator. 주로 쓰는건 autocast, multi-gpu 이정도만 알고 나머지는 쟤가 써놓은대로만 써왔음.
처음 세팅할 때
accelerater config-> 코드 내부에 다양한 accelerater 함수들 (unwrap, log, prepare 등등) -> 그리고 python 실행할 때 쓰는 accelerater 옵션들 (–mix-precision 같은거).
kohya-ss이 사람 코드 기준으로 하나하나 알아보려고 한다.
-
AI 기강 다지기
직장생활 1년 10개월 정도하면서 프로젝트 완성에만 초점을 두느라 대충 슥 보고 넘어갔던 개념들이 많아 지나온길, 써봤던거 돌아보며 개념좀 다시 잡고자 포스팅하게되었음.
특히 코드 보면서 “아 그런갑다~” 하고 넘어갔던 놈들 위주로 다시 리마인드 하면서 계속 적어나갈 예정
-
StableDiffusion 실습
-
표 병합
코드
def update_links(links, value): for h, w in links: table[h][w][0] = value def init_links(links): for h, w in links: table[h][w] = ['EMPTY', {(h, w)}] def update(command): if len(command) == 3: h, w, value = command h, w = int(h) - 1, int(w) - 1 _, links = table[h][w] update_links(links, value) else: value1, value2 = command for h in range(n) : for w in range(n) : value, links = table[h][w] if value == value1 : table[h][w][0] = value2 def merge(command): h1, w1, h2, w2 = map(int, command) if h1 == h2 and w1 == w2 : return h1, w1, h2, w2 = h1-1, w1-1, h2-1, w2-1 value1, links1 = table[h1][w1] value2, links2 = table[h2][w2] links = links1.union(links2) value = value1 if value1 != "EMPTY" else value2 update_links(links, value) for h, w in links : table[h][w][1] = links def unmerge(command): h, w = map(int, command) h, w = h - 1, w - 1 value, links = table[h][w] init_links(links) table[h][w][0] = value def print_(command): h, w = map(int, command) h, w = h - 1, w - 1 value, _ = table[h][w] return value # 테이블 및 value_storage 초기화 n = 50 table = [[["EMPTY", {(h, w)}] for w in range(n)] for h in range(n)] def solution(commands): answer = [] for command in commands: command_type, values = command.split(' ', 1)[0], command.split(' ')[1:] if command_type == 'UPDATE': update(values) elif command_type == 'MERGE': merge(values) elif command_type == 'UNMERGE': unmerge(values) elif command_type == 'PRINT': answer.append(print_(values)) return answer
-
표현 가능한 이진트리
코드
def expand_bin(bin_number) : i = 0 while len(bin_number) > 2**(i+1) - 1 : i += 1 return '0'*(2**(i+1) - 1 - len(bin_number)) + bin_number def possiblity_check(bin_number) : center = len(bin_number) // 2 if len(bin_number) == 1 : return True elif bin_number[center] == '0' : return not ('1' in bin_number[:center] or '1' in bin_number[center + 1:]) else: return possiblity_check(bin_number[:center]) and possiblity_check(bin_number[center + 1:]) def solution(numbers): answer = [] for number in numbers : bin_number = str(bin(number))[2:] bin_number = expand_bin(bin_number) answer.append(possiblity_check(bin_number)*1) return answer
- 프로그래머스 177
- 카카오 1
- 2020_카카오_인턴쉽 4
- 2020_KAKAO_BLIND_RECRUITMENT 7
- Algorithm 1
- 월간_코드_챌린지_시즌1 12
- 2021_KAKAO_BLIND_RECRUITMENT 7
- 2019_카카오_개발자_겨울_인턴십 5
- 2018_KAKAO_BLIND_RECRUITMENT 12
- 2019_KAKAO_BLIND_RECRUITMENT 7
- Summer/Winter_Coding(~2018) 12
- Summer/Winter_Coding(2019) 2
- 찾아라_프로그래밍_마에스터 3
- 2017_팁스타운 3
- 노트 4
- ML 18
- AI 18
- 월간_코드_챌린지_시즌2 3
- 기타 4
- Paper_Review 7
- 논문리뷰 18
- 실습 18