
subject-driven 모델 개발하던 중 보게 된 선행연구 NEGATIVE-GUIDED SUBJECT FIDELITY OPTIMIZATION FOR ZERO-SHOT SUBJECT-DRIVEN GENERATION.
DPO 라는걸 임커밋 오픈채팅방에서 누가 쏼라쏼라하던거 말로만 듣고 먼지도 모르는 상태에서 실험 결과를보고 안써볼 수 가 없었다. 어차피 학습 파이프라인 0-100 혼자 만들어둔 상태였기에 DPO 학습을 위한 dataloader, loss func 부분 추가하는건 그렇게 어려워 보이지 않아 바로 테스트해본 결과가 위의 이미지다(본인 와꾸임).
학습 데이터 수집을 위해 외주 맡긴 업체 씨발년들이 핸드폰으로 스크린샷 찍어서 위아래양옆 패딩 되어있고, 작은 이미지 사이즈 upscale해서 화질 개박살난 이미지, group 개판으로 지좆대로 섞어두고 이런 개쓰레기 데이터셋이 거의 반넘게 포진되어있던 터라 필터링하고 분류하는데만 거의 3주 넘게 썼다. 그럼에도 데이터셋이 워낙 개쓰레기라 학습 결과물이 처참했다 (데이터셋 생각하면 지금도 쳐죽이고싶음 ㄹㅇ).
- 강제 업스케일 된 이미지 영향을 받아 간혹 뿌옇게 된 이미지가 생성됨.
- foundation 모델의 한계로 한국 고유 domain 생성 능력 떨어짐 (한국 모델, 닭발, 뼈해장국, 냉면 등등).
- 상품설명, 조그만 제품이름 같은 작은 한글 텍스트 깨짐 (큰건 그나마 ㄱㅊ)
그런데 이게 왠걸, 먼지도 모르는 DPO 썼더니 한글텍스트 부분 빼고 거의 완치되었음. 이건 도의적으로 읽어줄 수 밖에 없는 논문이었음.
게다가 요즘 이미지 생성, 이미지 편집 모델은 대부분 학습 후 강화학습으로 한번 bake 해주는게 정배인 터라 꼭 이론적으로 알고있어야하는 연구라고 생각됨.
근데 논문이 진짜 appendix에 친절하게 하나부터 열까지 차근차근 설명을 잘해줘서 이론 부분은 그렇게 어렵지 않았는데, 실험부분에 세팅을 개같이 꼬아놔서 너무 이해하기 힘들었음.
- 실험 이해 어렵고 많은거 이건 자연어 논문 종특이라 진짜 짜증나는데 진짜 열심히 읽고 이해했다.
그리고 DPO의 아들인 GRPO도 살짝 맛만 보겠다.
그래서 이 포스트는 아래의 4가지에 대한 해답을 얻기 위함임.
- DPO가 그래서 원리가 뭔교?
- 어떻게 해야 극대화 할 수 있는교?
- 이미 DPO, RLHF로 학습 된 모델에 fine-tuning 같은거 해도됨?
- GRPO 얘는 머임
DPO가 뭐임?
DPO논문이 근래 읽은 논문, 아니 여태껏 읽은 논문 중 개지렸던 top-3안에 든다.
- 내 픽: GAN, SCORE-BASED GENERATIVE MODELING …, Auto-Encoding Variational Bayes, DDPM 등등
이 논문의 본질은 RLHF loss를 서커스해서 깔끼하게 바꾼거 보단 PPO 같은 Actor-Critic 알고리즘의 암덩어리인 critic을 도려낸거라 생각한다.
Section 5에 그 내용이 자세히 나와있긴한데 이건 따로 DPO 포스트를 써야하는 양이라 이 포스트에서는 DPO 껍데기만 살짝 보겠다ㅇㅇ
내가 생각한 DPO를 한줄로 요약하면 아래와 같다.
모델의 고점은 유지하고 저점을 높여라
RLHF에서 태어난게 DPO이고, RLHF 자체가 “아 생성모델 임마 이거 진짜 빨딱선날은 좋은데 간혹 개 ㅂㅅ이 되네. 이거 ㅂㅅ짓좀 안하게 할수 없노?”를 겨냥하고 연구한걸로 이해했고 DPO도 수식을 보면 ㅂㅅ짓 못하게끔 수식이 구성되어있다.
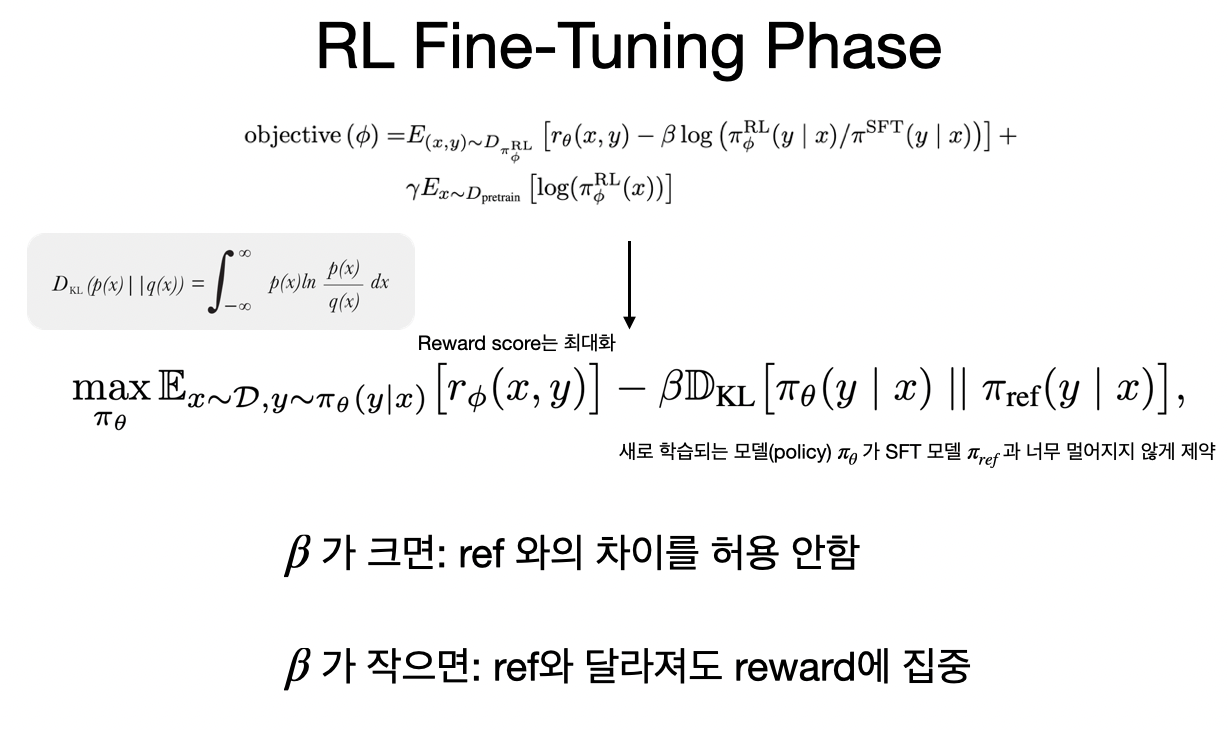
우선 RLHF는 이렇게 생겼다.
- 보상높은 output만 출력하도록 하면서: ㅂㅅ짓하지말고
- 학습할 모델 $\pi_{\theta}$는 기존모델 $\pi_{ref}$와 동떨진 출력 내면안된다: 잘하는거 (고점)는 유지해라
기존 RLHF (PPO)의 문제점은 학습 불안정 (critic) 및 복잡한 학습 과정이다. 자세한건 DPO 리뷰 포스트를 확인하자.
\[\mathcal{L}_{\text{DPO}}(\pi_{\theta}; \pi_{\text{ref}}) = -\mathbb{E}_{(x, y_w, y_l) \sim \mathcal{D}} \left[ \log \sigma \left( \beta \log \frac{\pi_{\theta}(y_w \mid x)}{\pi_{\text{ref}}(y_w \mid x)} - \beta \log \frac{\pi_{\theta}(y_l \mid x)}{\pi_{\text{ref}}(y_l \mid x)} \right) \right]\]이 수식이 RLHF 깍아서 만든 DPO loss 함수다. 이걸 업데이트 하기 위해 $\theta$로 미분 때리면 아래와 같은 형식이 나온다.
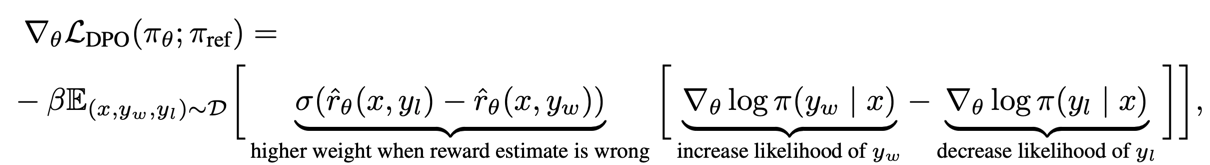
슥 보면
“음 win은 likelihood 높게되도록 유지하고, lose일 때 likelihood 낮게(ㅂㅅ짓 못하도록) 하도록하는군. 그리고 왼쪽에 시그모이드로 가중치 조절을 하는구만ㅇㅇ”
하고 넘어갈 수 있었지만, 묘하게 먼가 거슬리는게 있었음. likelihood 줄이는 방향으로 업뎃하도록 하는걸 내가 본적이 있던가? 저래도 되나? 하는 생각이 들었음.
이거는 좀 완벽한 이해를 위해 시나리오를 짜서 분석해봐야함ㅇㅇ
| $\log{\pi_w}$ (Win) | $\log{\pi_l}$ (Lose) | 상태 진단 | DPO 가중치 $\sigma(\hat{r}_l - \hat{r}_w)$ | 현상 분석 |
|---|---|---|---|---|
| 높 | 높 | 헷갈림 | 0.5 (중간) | 초반 학습 상태라 보면됨. 보상 차이가 0에 가까워 적당한 강도로 학습됨. |
| 높 | 낮 | Best | 0 (소멸) | 이미 잘하고 있음. Gradient가 0으로 수렴하여 파라미터가 변하지 않음. |
| 낮 | 높 | Worst (좆됨) | 1 (최대) | 정답보다 오답을 더 선호하는 꼬롬한 상태. 보상 차이가 양수(+)가 되어 시그모이드가 1에 가까워짐. 풀파워로 업데이트. 아마 $\beta$크면 이 때 박살날 위험이 생김 |
| 낮 | 낮 | OOD / 박살 | 0.5 (중간) | 오답을 확신하지는 않으므로 Worst보다는 나은 상태 |
그래서 DPO 어떻게 쓰라는거임
일단 자연어 처리는 알빠노고, 나는 이미지 생성에 DPO 쓰는것만 분석한다.
SFT로 이미지 생성 학습 시켜놓고 win/lose 뽑아서 설문 돌리는 돈지랄은 대기업햄들이나 할 수 있고, 돈없고 자원부족하고 시간 촉박한 스타트업 다니거나 가난한 대학원들은 꿈도 못꾸는 방식임.
그래서 보통 self-play로 win case는 풀컨디션주고 만들고, lose case는 일부러 어디하나 부러트려서 학습 세트를 만들어쓴다.
그리고 $\beta$의 크기도 자연어에 비해 존나게 크게 잡는데 10 ~ 1,000 까지 다양하다.
Self-Play DPO 학습
| Win case | Lose case | $\log{\pi_w}$ | $\log{\pi_l}$ | 현상 분석 |
|---|---|---|---|---|
| GT 이미지 | 생성한 이미지 | 낮게 출발 | 높게 출발 | $\sigma$ 가중치 존나 커지면서 모델의 생성 분포를 억지로 찢어서 GT로 끌고감. Mode Collapse 직행열차 |
| 생성된 이미지 | 컨디션 박살내서 생성 | 높게 출발 | 낮게 출발 | 이미 정답을 선호해서 $\sigma$ 가중치 낮게 출발. 학습 잘 안됨. 전기세 낭비임 |
| GT 이미지 | 컨디션 박살내서 생성 | 낮게 출발 | 낮게 출발 | 그냥 Contrastive Learning임. SFT보다는 조금 더 ‘분별력’을 키워주는 정도고 DPO의 맛을 못냄 |
gemini는 3번째 방법이 그나마 낫다고하는데 나는 2번째방법으로 밖에 안해봄.
학습이 안 이루질꺼같지만 오히려 많이하면 이상해짐 (물론 베타가 컸었다).

위는 DPO 적당히 돌린케이스고, 아래는 존나게 돌렸을 때 요상한 격자무늬가 생긴다. FLUX든 QWEN이든 DPO 많이하면 distribution 박살 보다는 뭔가 이미지 전체적으로 아티팩트가 생긴다 (격자, 어두워짐 등)
$\beta$ 에 대하여
DPO가 RLHF의 아들인건 맞지만 $\beta$의 차이는 정 반대의 역할을 해버린다. 그리고 자연어와 다르게 Diffusion는 loss가 거의 0.05 ~ 0.1 이렇기 때문에 기본적으로 $\beta$ 도 크게 잡아줘야 한다.
- 자연어: 1보다 작게
- 이미지: 10, 100, 1000 단위
| $\beta$의 의미, 역할 등 | RLHF | DPO |
|---|---|---|
| 의미 | 보상은 알아서 챙기고 SFT랑 다르면 뒤진다 | 틀리면 (reward) 줄빠다 맞음 |
| 역할 | $\beta$ 커지면 쫄아서 보상 무시하고 SFT랑 비슷하게 유지할라고함 | 커지면 모델 확확 바뀜. |
| 비유 | “안전벨트” (클수록 못 움직이게 꽉 잡음) | “몽둥이 크기” (클수록 한 대 맞을 때 뼈가 부러짐) -> 안맞을라고 파라미터 호다닥 바꿈 |
쉽게 생각해서 RLHF랑 반대의 역할을 한다ㅇㅇ.
DPO 된 foundation 모델에다가 학습 해도됨?
최근에 이직한 회사는 foundation 모델을 만드는 것을 목표로해서 여기서 살짝 관심이 멀어지긴 했는데, 보통 작은 스타트업이나 대학원에서는 연구용으로 오픈한 foundation 모델에 주짓수를 걸어야한다.
그런데 문제는 오픈된 foundation 모델이 보통 Distillation이나 DPO, RLHF같은 걸로 한번 구워진 상태라는거다.
Q. 아니 강화학습으로 distribution 꽉 쪼매놨는데 여기에 학습을 해도되는건가?
A. 솔직히 권장하지 않는다.
RLHF나 DPO가 모델에 하는짓: 모델의 파라미터(Weight)들을 “인간이 좋아하는 좁고 뾰족한 최적점(Local Minimum)”으로 강제로 밀어 넣음.
- Base Model: 아직 덜 굳은 점토. 어디로든 빚을 수 있음. (유연함)
- RLHF/DPO Model: 오븐에서 딱딱하게 구워진 도자기. (이미지 퀄리티는 쩔지만 유연성 제로)
그래서 상업용/연구용으로 오픈한 baked 된 모델은 fine-tuning하면 좋지않다. 그나마 LoRA붙여서 조심스럽게 학습은 괜찮지만 이거는 연구적인 성과가 하나도 없기에 아무 의미가 없다.
그러면 나같은 좆소 대학원 나부랭이는 뒤지라는거임?
ㅇㅇ 어쩔수 없다. 연구를 하고 싶으면 똥꼬쇼해서 base 모델 얻어내고, 상업적 목적이면 몰래 LoRA 학습해라.
GRPO (흙수저의 반란)
이건 논문은 아직 못봤지만 흙수저용 학습에 딱 맞는 PPO 기반 강화학습인듯?
DeepSeek-R1맞나? 뭐 어쨌든 여기에서 만들어낸거같음ㅇㅇ.
DPO, GRPO 두 논문의 공통점이 있는데 바로 PPO (RLHF)에 불안정함의 범인인 critic(Value function)을 해결했다는 것이다.
우선 나는 강화학습을 DPO로 배웠기때문에 PPO, actor-critic 만져본적도, 빨아본적도 없다. 고로 이론적으로 빈틈이 상당히 많을것이므로 누군가 이걸 읽고있다면 감안해서 배우도록.
- 장님에게 코끼리 고추를 만지게하고 그걸 설명하라하면 제대로 할 수 있을까? 거대한 여의봉이라고 생각할것이다.

이 흉악한 수식은 DPO section 5.2 에 나온다.
- 위의 수식은 임의의 reward function에 대한 PPO 업데이트 수식이므로 굉장히 일반화가 되어있기에 이걸보고 critic에 대한 설명을 해도 문제가 되지 않을꺼같다.
PPO기반 actor-critic 학습은 policy (새로학습할 모델)를 reward가 높아지는 방향으로 학습하는 것을 목표로한다.
그러나 여기서 문제가 하나 있는데 몇점을 받으면 잘하는거고 몇점을 받으면 못하는걸까?
97점 받아와서 잘했다고 칭찬했는데 990점 만점이었다면?
그래서 PPO는 모델의 output이 높은 reward가 되도록 하는 것이 목표지만, critic은 reward로 받아낸 점수가 높은건가? 에 대한 기준을 잡아주는 훈수꾼이다.
왼쪽에 수식은 입력 $x$를 받아서 만든 $y$에 대한 reward 점수다.
바로 오른쪽 critic은 수식대로 생각해보면 입력 $x$에 대해 모델이 내뱉을 수 있는 모든 $y$에 대해서 reward 평균을 구한것이다.
아들내미가 시험을 봐서 80점 받아왔고 몇점만점인지 모르는 상태에서, 같은 시험을 본 모든 이들의 평균을내서 점수를 높게 받은건지 빠따를 쳐야하는지 평가하겠다는 것.
RLHF에서는 이 critic 해결을 못해서 논문에서는 숨키고, 몰래 코드상에서 critic function 만들어서 학습했다고 한다 (gemini가 그랬음).
그래서 이론적으로 임의의 두 reward 함수에 대해 $r(x, y) = r’(x, y) + f(x)$ 라면 어느걸쓰든 동일한 결과물(policy)을 낸다라는 거에대한 증명을 통해, 무수히 많은 $r(x, y)$ 중에 critic이 0이 되는 세팅을 갖도록한 것이 바로 DPO이다.
- DPO의 진정한 진가는 RLHF 수식 서커스가 아니라 critic을 도려낸것.
그럼 GRPO는?
Group Relative Policy Optimization이 풀네임이고 아까 critic이 입력 $x$ 에 대해 모델이 낼 수 있는 무한한 답변 $y$들의 reward 평균이 critic이라고 했는데
그냥 아 몰랑 걍 $y$ 몇십개 평균을 critic으로 쓸란교ㅅㅅ
해버린게 GRPO라고 한다.
실제 GRPO 서커스 방식이 논문을 안읽어서 구체적으로 이해는 안되는데 아래 순서처럼 하는거 같음
- SFT 분신술써서 모델 2개 $\pi_{\theta}$, $\pi_{old}$ 만들어냄
- $\pi_{old}$로 답변 64개 뽑아냄. 그래서 평균 이상인 놈들은 win으로 삼고, 평균이하는 lose로 삼음.
- 64개 평균내서 critic 삼고 $\pi_{\theta}$ 얘만 GRPO 학습 조짐 ($\pi_{old}$ 는 freeze).
- $\pi_{\theta}$ 어느정도 학습되면 하나는 $\pi_{old}$로 삼고, 나머지 하나는 그대로 $\pi_{\theta}$ 그대로 세팅해서 다시 1번 부터 반복
- $\pi_{old}$ 를 계속 업데이트 해준다.
여기서 핵심은
- DPO와 달리 reward가 실제로 존재함. 다만 critic 없이 평균으로 그 역할 대체
- DPO 처럼 win/lose 만들 필요 없음. 그냥 몇십개 생성해서 그걸로 critic 삼아서 PPO 학습
이미지에 이거 GRPO 모델있는가 보기전에 GRPO 원문을 먼저 읽어야할꺼같긴 한데 ㅅㅂ 자연어 논문은 진짜 씹 헬이라 읽기싫은데 실제로 써보고 할람녀 봐야하는ㄷ제