- Reference
- Background
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Star Generative Adversarial Networks
- 4. Implementation
- 5. Experiments
Full Citation: “Choi, Yunjey, et al. “Stargan: Unified generative adversarial networks for multi-domain image-to-image translation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.”
Link to Paper: https://arxiv.org/abs/1711.09020
Conference Details: CVPR 2018
수정예정
Reference
Background
StarGAN의 부제는 Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation 이다. 우선 이 논문을 이해하려면 두가지 키워드 “Domain”과 “Image-to-Image Translation”을 이해하고 있어야하므로 잠깐 언급하고 논문 리뷰로 넘어가겠다.
Domain
본 논문에서는 Domain란 용어를 “Set of images sharing the same attribute value”라고 정의했는데 attribute value는 이미지에서 나타나는 특징을 의미한다. 예를들어 아래의 이미지의 attribute value는 [남성, 갈색머리, 웃는모습….] 이 될 수 있다. 그리고 Domain은 이미지 데이터셋이 공통적으로 가지고 있는 attribute value이다.

Image-to-image translation
UC Berkeley의 Alexei A. Efros 교수의 연구실의 연구 중 ECCV 2016에 나왔던 Colorful Image Colorization이라는 논문이 있는데 아래의 그림처럼 흑백영상을 컬러 영상으로 바꾸는 시도를 했었다고 한다. 이처럼 한 이미지의 Domain을 다른 Domain으로 바꾸는 연구가 Image-to-image translation 연구의 시작이었을 것으로 추측한다.

아래 그림처럼 아무 얼룩말 이미지를 생성하는것이 아니라 input의 domain만 바꾸는 것이 바로 image-to-image translation이다

Abstract
최근까지 image-to-image translation 연구가 많은 발전을 이룬건 사실이지만 2개보다 많은 domain을 다루는데엔 큰 한계점이 있다. 바로 translation domain pair당 하나의 generator모델이 필요하다는 것이다. 그래서 이 논문은 하나의 generator로 여러 domain으로 translation이 가능한 방법을 제안하고자 한다.
1. Introduction
Image-to-image translation은 fig 1 처럼 이미지의 특정 attribute value를 바꾸는 것이고, GAN 논문이 나온 이후 많은 발전이 있었다. 하지만 Abstract에서도 말했듯 기존 연구들은 명확한 한계점이 있다.
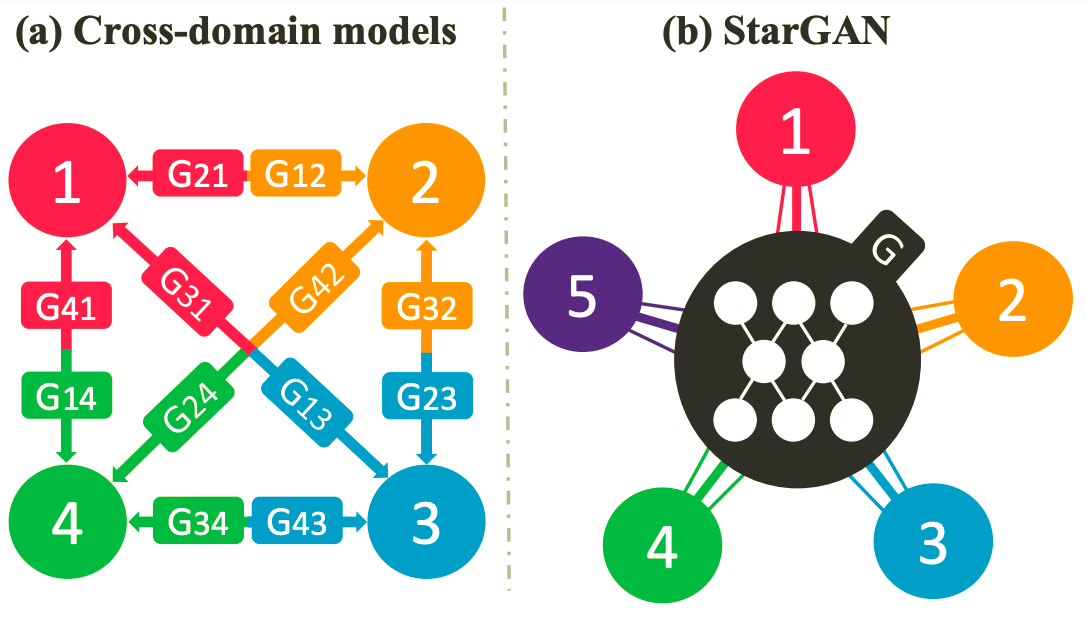
- inefficient
- $k$개의 domain에 대해 translation을 하고 싶으면 $k(k-1)$개의 generator가 필요하다.
- 기존 연구는 위 그림 (a) 처럼 각 domain마다 하나의 generator가 필요하며 1번 domain에서 (2, 3)번 domain으로 translation을 하기 위해선 2개의 generative 과정을 거쳐야한다. 하지만 본 논문의 starGAN은 그럴 필요가 없이 자유롭게 domain간 translation이 가능하다.
- ineffective
- 기존 연구들의 generator는 특정 domain의 특징만 학습하기 때문에 이미지내에 존재하는 여러가지 attribute value들을 활용하지 못함. 따라서 결과물 이미지의 quality가 떨어지게됨
- incapable
- 서로다른 dataset을 학습시킬 수 없음. section 3.2에서 자세히 다룰 예정
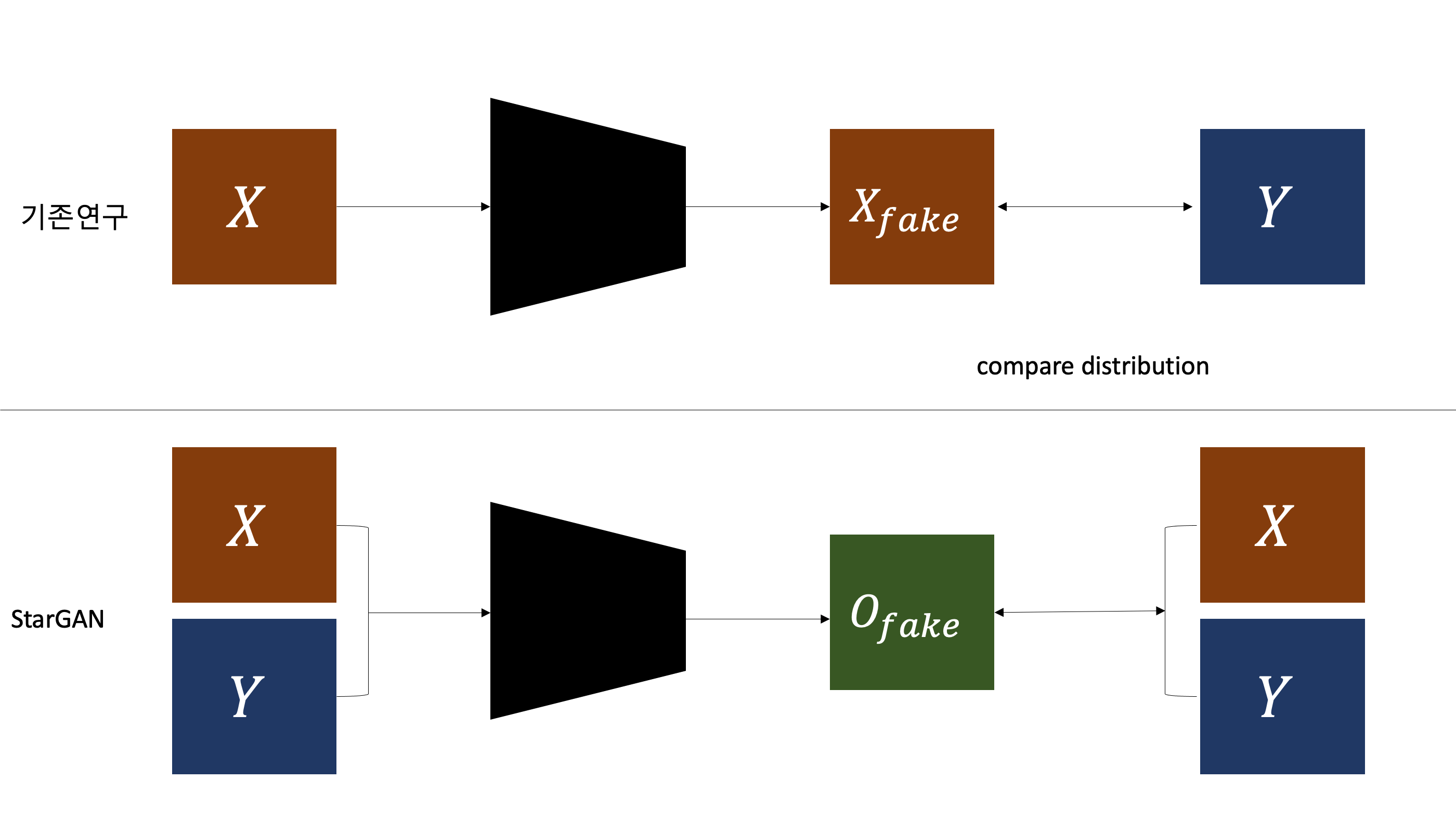
직관적인 이해를 위해서 이전 image-to-image translation 학습방법과 starGAN의 학습방법의 차이를 보여주는 이미지를 만들어보았다. 기존 연구들은 input domain 이미지와 target domain 이미지를 분리해서 input 이미지만 학습을 시켜 비교를 통해 distribution 의 차이를 좁혀나갔다면, starGAN은 전체 데이터셋을 training으로서 사용한다. 그렇기 때문에 위에서 언급한 3가지 기존연구들의 한계점을 극복할 수 있는 것이다.
2. Related Work
- Generative Adversarial Networks
- 이미지 생성에 매우 뛰어난 성능을 보여주는 연구
- Conditional GANs
- 무작위로 이미지를 생성하는 GAN에 조건문을 추가해 원하는 이미지를 생성할 수 있게한 연구
- Image-to-Image Translation
- pix2pix, UNIT, CycleGAN, DiscoGAN 등등 여러 image-to-image translation 연구가 존재하지만 위에서 언급한 한계점이 있다.
3. Star Generative Adversarial Networks
우선 section 3.1에서 multi-domain 학습이 가능케하는 Loss 함수들을 살펴볼 것이고, section 3.2에선 different dataset을 jointly-training을 가능케 해주는 mask vector에 대해서 살펴볼 것이다.
[figure 3]
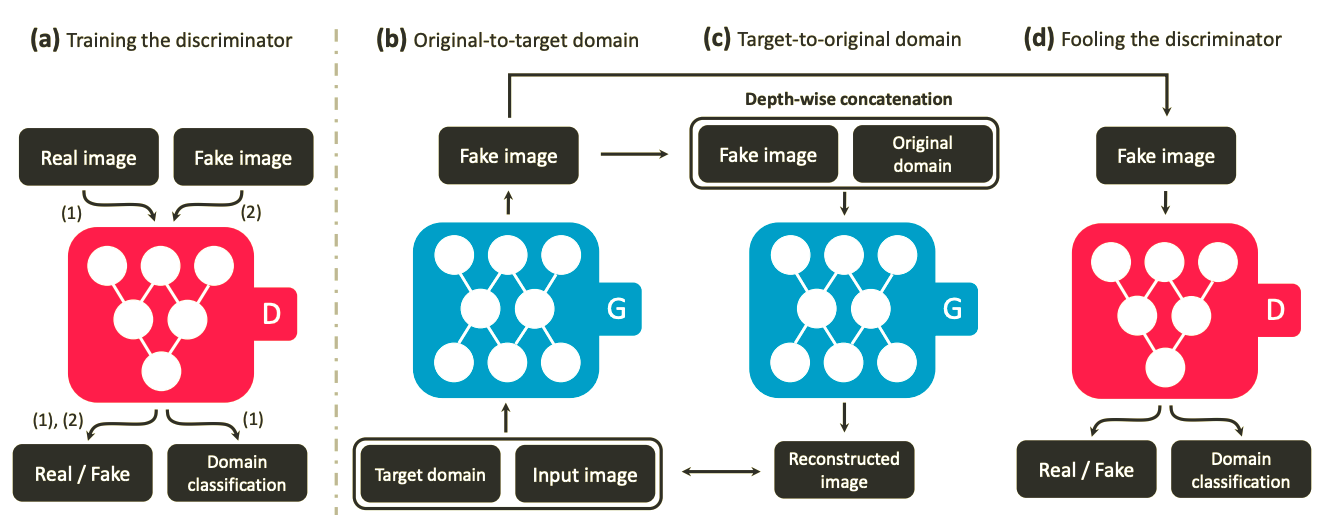
- Generator
- 오리지널 GAN에서도 그러했듯이 generator는 확률변수이다. starGAN에서의 generator는 특정 domain label의 이미지 확률분포로의 mapping을 담당하게 되는데 그렇게 하기 위해서는 generator는 위 그림 처럼 입력값으로 input과 mapping하고자 하는 domain의 라벨값을 입력으로 받게된다. 학습시에는 mapping하고자 하는 domain을 ramdom하게 생성해서 학습 하는데 이는 input 이미지를 flexible하게 translate 해준다.
- Discriminator
- starGAN에서 Discriminator은 output으로 2가지를 출력하는데 하나는 input이 원본데이터일 확률을 출력하고 나머지 하나는 input 이미지의 domain label의 예측값을 출력한다.
오리지널 GAN이 이미지의 확률분포만 다루었다면 starGAN의 경우 이미지의 확률분포 뿐만 아니라 이미지의 domain 정보의 확률분포 또한 같이 다룬다.
3.1. Multi-Domain Image-to-Image Translation
이 section 에서는 starGAN이 multi-domain task를 수행할 수 있게 해주는 Loss 함수에 대해서 설명한다. training에 사용되는 loss는 총 3가지로 이루어져있다.
- Adversarial Loss
- Domain Classification Loss
- Reconstruction Loss
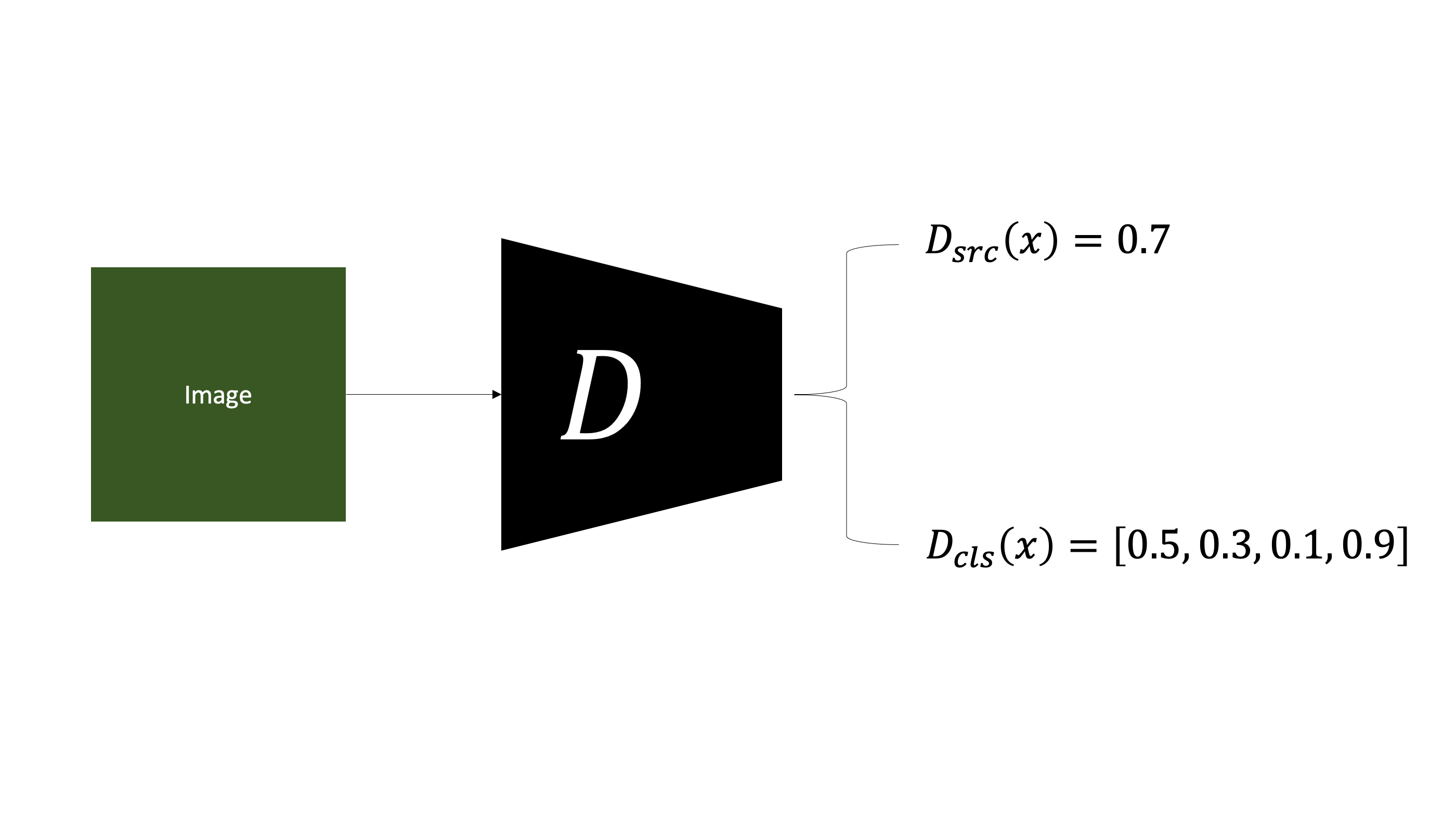
논문에 등장하는 $D_{src}$와 $D_{cls}$는 각각 $D$가 출력하는 input에 대해 진짜이미지일 확률값과 domain 예측값을 의미한다.
Adversarial Loss
\[\boldsymbol{L}_{adv} = \mathbb{E}_{x}\left [ \log D_{src}(x) \right ] + \mathbb{E}_{x, c}\left [ \log(1 - D_{src}(G(x, c))) \right ]\]Condition GAN의 Loss와 똑같다. starGAN은 이미지와 domain의 확률분포를 다루다고 했는데 \(\boldsymbol{L}_{adv}\)는 이미지에 대한 확률분포를 담당하는 Loss함수이다. 해석하면 input이 진짜일 확률의 기대값 + input이 가짜가 아닐 확률의 기대값이 된다. GAN과 마찬가지로 $D_{src}$는 \(\boldsymbol{L}_{adv}\)를 maximize 하도록 하고 $G$는 \(\boldsymbol{L}_{adv}\)를 minimize 하도록 한다.
Domain Classification Loss
\[\boldsymbol{L}^{r}_{adv} = \mathbb{E}_{x, c^{'}}\left [ -\log D_{cls}(c^{'}\mid x) \right ] \\ \boldsymbol{L}^{f}_{adv} = \mathbb{E}_{x, c}\left [ -\log D_{cls}(c\mid G(x, c)) \right ]\]명칭에서도 알 수 있듯이 \(\boldsymbol{L}_{adv}\)는 domain의 확률분포에 관한 Loss 함수다. 이는 그냥 $D$가 출력하는 domain label predict vector에 대해 cross entropy loss 값이다. 실제 domain label vector와 예측 domain label vector간의 차이를 줄이는게 목표다. 다만 domain label vector의 합은 1이 아니다. 왜냐하면 한 이미지는 다수의 attribute vector를 가지고 있기 때문에 각 attribue label 에 대한 확률값이다.
Reconstruction Loss
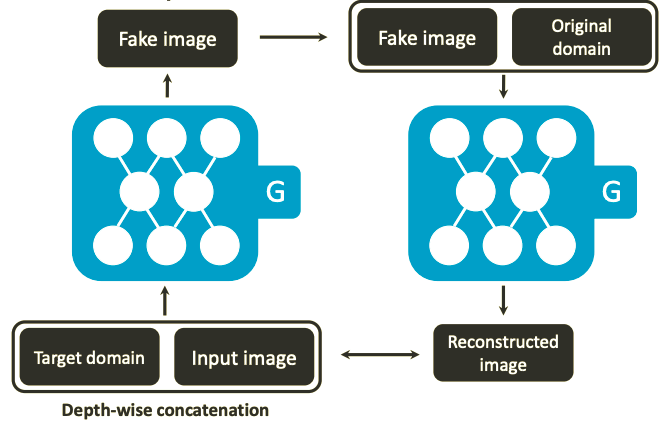
Reconstruction loss가 image-to-image translation의 핵심 역할을 담당한다. Image-to-image translation의 목표는 input이미지의 특정 domain만 바꾸는 것이지 완전히 새로운 이미지를 생성하는것이 목표가 아니다. 즉 이미지의 domain을 제외한 나머지 부분은 변함이 없어야한다. 이런 task를 하기 위해 generator 가 생성하는 이미지가 input 이미지와 차이가 크게 나지 않도록, reconstruct을 했을 때 다시 돌아올 수 있을 정도의 수준으로 생성되기 위해 \(\boldsymbol{L}_{rec}\)가 사용된다..
$c$ : target domain
$c^{‘}$ : input domain
Full Objective
\[\boldsymbol{L}_{D} = -\boldsymbol{L}_{adv} + \lambda_{cls}\boldsymbol{L}^{r}_{cls}\\ \boldsymbol{L}_{G} = \boldsymbol{L}_{adv} + \lambda_{cls}\boldsymbol{L}^{f}_{cls} + \lambda_{rec}\boldsymbol{L}_{rec}\]$\lambda_{cls} = 1$
$\lambda_{rec} = 10$
최종적으로 목적함수는 위와같이 된다.
3.2. Training with Multiple Datasets
위의 목적함수를 이용함으로서 starGAN이 multi-domain translation이 가능하다는 것을 보여줬는데, starGAN의 또다른 강점은 바로 다른 데이터셋을 묶어서 훈련 시킬 수 있다는 것이다. 서로다른 데이터셋을 한번에 훈련시킬 때 고려해야할 사항은 바로 label vector다. 아래와같은 서로다른 두 데이터셋의 라벨이 다를 때, dataset A의 이미지를 dataset B의 domain 중 하나로 translate 하면 그 이미지는 dataset B의 label을 가지게 되는데 이렇게 되면 reconstruct을 할 때 문제가 생기게된다. 이러한 문제를 해결하기 위해 각 데이터셋의 어떤 라벨을 이용할건지를 표시하는 mask vector를 사용한다.

Mask Vector

mask vector는 위의 그림처럼 각 데이터셋의 라벨 벡터를 concatenate를 한뒤 마지막에 n차원 mask vector $m$을 붙여준다. translate하고자 하는 데이터셋의 label vector 및 mask vector를 제외하곤 나머지는 0으로 만들어서 사용하게 된다. 이 예시에 대한 자료는 논문의 appenddix에 자세하게 나와있다.
Training Strategy
이 부분이 이해하기 가장 어려운 부분이었는데 different datasets를 training시켜도 mask vector로 translate하는 dataset을 명시하기 때문에(명시되지 않은 다른 데이터셋들의 label은 무시) $D$는 명시된 dataset domain vector의 distribution을 잘 생성해내서 classification error가 줄어든다라는 내용이 아닐가 생각된다.
4. Implementation
Improved GAN Training
2017년 GAN의 Loss함수를 획기적으로 바꾼 WGAN 연구가 발표되었다. 기존의 GAN보다 학습시키기도 훨씬 싶고 더 강력한 성능을 발휘했지만 WGAN에도 약간의 단점이있었다. Loss함수의 특정 조건을 만족시키기 위해 학습 parameter를 특정 범위로 cliping 했는데 이러한 부분을 개선한 것이 바로 WGAN-GP다. 이 논문이 나온 이후로 GAN의 후속 연구들은 모두 WGAN-GP의 Loss 이용하고 있다고 봐도 무방할 정도로 좋은 성능을 자랑하기에 이 논문도 WGAN-GP Loss 를 사용했다.
-
Original \(\boldsymbol{L}_{adv}\)
- \[\boldsymbol{L}_{adv} = \mathbb{E}_{x}\left [ \log D_{src}(x) \right ] + \mathbb{E}_{x, c}\left [ \log(1 - D_{src}(G(x, c))) \right ]\]
-
WGAN-GP
- \[\boldsymbol{L}_{adv} = \mathbb{E}_{x}\left [ D_{src}(x) \right ] + \mathbb{E}_{x, c}\left [ D_{src}(G(x, c)) \right ] - \lambda_{gp}\mathbb{E}_{\hat{x}}\left [ (\left \| \bigtriangledown _{\hat{x}D_{src}(\hat{x})} \right \|_{2}-1)^{2} \right ]\]
Network Architecture
$G$는 CycleGAN의 구조를 사용했다. 부록에 자세이 나와있음. $D$는 pix2pix의 patchGAN 모델을 이용했다.
5. Experiments
실험 부분은 내가 설명하는것 보다 그냥 쭉 읽어보는게 나을것 같다는 판단이 들어서 생략하도록 하겠다. 살짝 요약하면
- baseline 모델 3개와 single-starGAN의 Celeb A, RaFD 데이터셋에대한 정성, 정량 평가
- CelebA + RaFD 의 Joint-training 실험결과
- mask vector의 역할 및 성능
이렇게 간단하게 요약해볼 수 있다.