- Reference
- Relation Classification
- Introduction
- Architecture
- Feature Extracting
- Output
- Back Propagation
- 실험(pass)
여러가지 NLP process 중 하나이면서 정말 중요한 Relation Classification(Relation Extraction)을 Convoluton filter를 이용하여 해결하는 방법을 제시했던 논문이다.
Reference
Relation Classification
Relation Classification 또는 Relation Extraction(이하 RE, 사실 두개가 정확히 같은것인지는 모르겠음)문제는 여러 NLP 문제(감성분석, S2S 등등) 중 하나이다. 처음보는 분야라 감이 안잡혀서 5~10분정도 분량의 간략한 블로그글이나 설명을 보고싶었는데 아쉽게도 그러한 포스트가 존재하지 않았다. 앞으로 이와 관련된 논문을 여러편 더 읽어야 RE에 대한 이해가 완벽해 지겠지만, 우선 이 논문을 읽은 이해를 바탕으로 간략하게 RE문제를 요약하고 본격적으로 논문 리뷰를 해보겠다. RE문제는 한 문장에서(또는 문단)에서 두개(혹은 그 이상)의 명사들간의 관계를 맞추는 문제이다.
The [fire]\(_{e_1}\) inside WTC was caused by exploding [fuel]\(_{e_2}\)
이러한 문장이 있을 때 $e_1$과 $e_2$의 관계는 인과관계이다. 이렇게 문장내에서 두개의 명사간의 관계(Cause-Effect, Component-Whole, Entity-Origin 등등) 를 맞추도록 학습시키는 것이 바로 RE문제이다. 학습 데이터도 직관적이지 않고 좀 복잡하게 생겨서(나도아직 실습 안해봄) 이해하기 어렵다. 이 논문에서는 이러한 RE문제를
given a sentence $S$ with the annotated paris of nomials $e_1$ and $e_2$, we aim to identify the relations between $e_1$ and $e_2$
라고 정의하고있다. Vision 분야는 문제해결에 대부분 CNN을 기반으로 접근하는 반면에 이 문제해결에는 2가지 접근방법이 있다고한다.
- Feature-Base
- Kernel-Base
이 논문은 Feature-Base 방법으로 RE문제를 해결했다. Feature-Base 방법은 우리가 흔히아는 Feature(단어의 밀집벡터, input 이미지 등등)를 input으로 모델을 학습시켜 문제해결을 하는것을 의미한다. 그러나 Kernel-Base는 사실 모르겠다. 예전 SVM공부할 때, …decision boundary를 좀 유연하게 긋기 위해서 input의 차원을 더 높은 차원에 projection시켜서 고차원에서 boundary 긋고 다시 차원을 원상복구하는…, 이러한 차원을 갖고놀게 해주는 함수가 kernel함수 인것은 아는데 이게 어떻게 쓰이는지 이걸로 어떻게 모델을 구성하는지는 모르겠다. Kernel-Base RE문제 해결 논문을 보고 싶으면 여기를 보길 바란다. 진짜 어렵다.(kernel method에 대한 간략한 설명).
Introduction
위에서 말했듯이 이 논문은 RE문제를 Feature-Base로 문제를 해결했다. 늘 그렇듯이 RE에 대한 기존의 Feature-Base 방법들을 까면서 시작하는데 한마디로 요약하자면 “Raw한 문장(Sequence)에서 학습을 위해 Feature뽑아야하는데 잘 뽑으면 좋은 성능이 나오지만 잘못뽑으면 성능이 매우 안좋아진다.” 라고 말하고있다. 나도 RE 논문이 이게 처음이라 이 논문이전의 RE 트렌드에대해 모르지만 RE를 위해 Feature를 뽑는 전처리가 매우 어렵고 힘들다라는것을 유추해볼 수 있다. 이 논문이 주장하는 바는 “우리는 모델 외적으로 Feature를 뽑기위한 전처리 필요없다. 모델내부에서 해결한다. 그리고 성능도 더 좋다.” 이렇게 요약할 수 있다.
Architecture
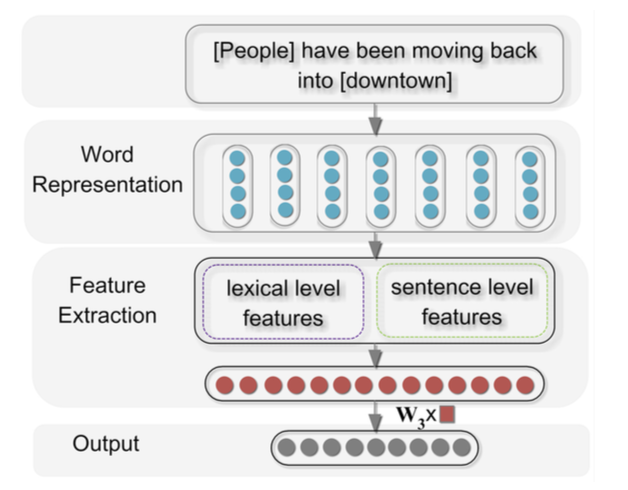
이 모델을 간략하게 설명하자면
- Raw한 input 문장이 들어온다.
- input의 각 string을 밀집벡터(임베딩벡터)로 mapping 시켜준다.
- 밀집벡터에서 2개의 정보를 뽑는다.
- Lexical level features
- Sentence level features
- 두개의 Feature들을 concat해준다.
- Softmax를 이용해 출력층을 Relation 갯수만큼의 확률분포로 만들어준다.
3단계가 액기스이고 전부이기 때문에 이것만 이해하면 된다.
Feature Extracting
위에서 말했듯 이 논문에서 제안한 RE 해결 방식은 한 문장에서 2가지 Feature(정보)를 추출한다.
- Lexical Level Feature(단어 단위 정보)
- Sentence Level Feature(문장 단위 정보)

두가지 feature extracting에대해 예시를 들어보면 위 그림처럼 한 집단내에서 한사람에 대한 정보를 2가지로 볼 수 있다.
- 개인 단위 정보 - Lexical Level Feature
- 집단 단위 정보 - Sentence Level Feature
이런식으로 한 문장내에서 특정 단어 하나에 대해서 2가지씩 정보(feature)를 뽑는 것이다.
Lexical Feature
this paper uses generic word embeddings as the source of base features. We select the word embeddings of marked nouns and the context tokens.
논문에 나온 Lexical Feature를 뽑는 방법을 그대로 가져왔다. 그런데 아직 NLP에대한 이해도가 많이 떨어지다보니 이게 정확히 뭔지 모르겠다. 위에서 설명은 했지만 뭘하는건지는 알겠다, 하지만 어떻게 하는것인지는 모르겠다… 하여튼 저 방법을 이용해 Lexical Feature를 뽑는다고 한다.

Lexical Feature를 추출한 결과는 이런식으로 뽑아지고, 형태는 벡터형태로 나오게된다.
Sentence Level Feature
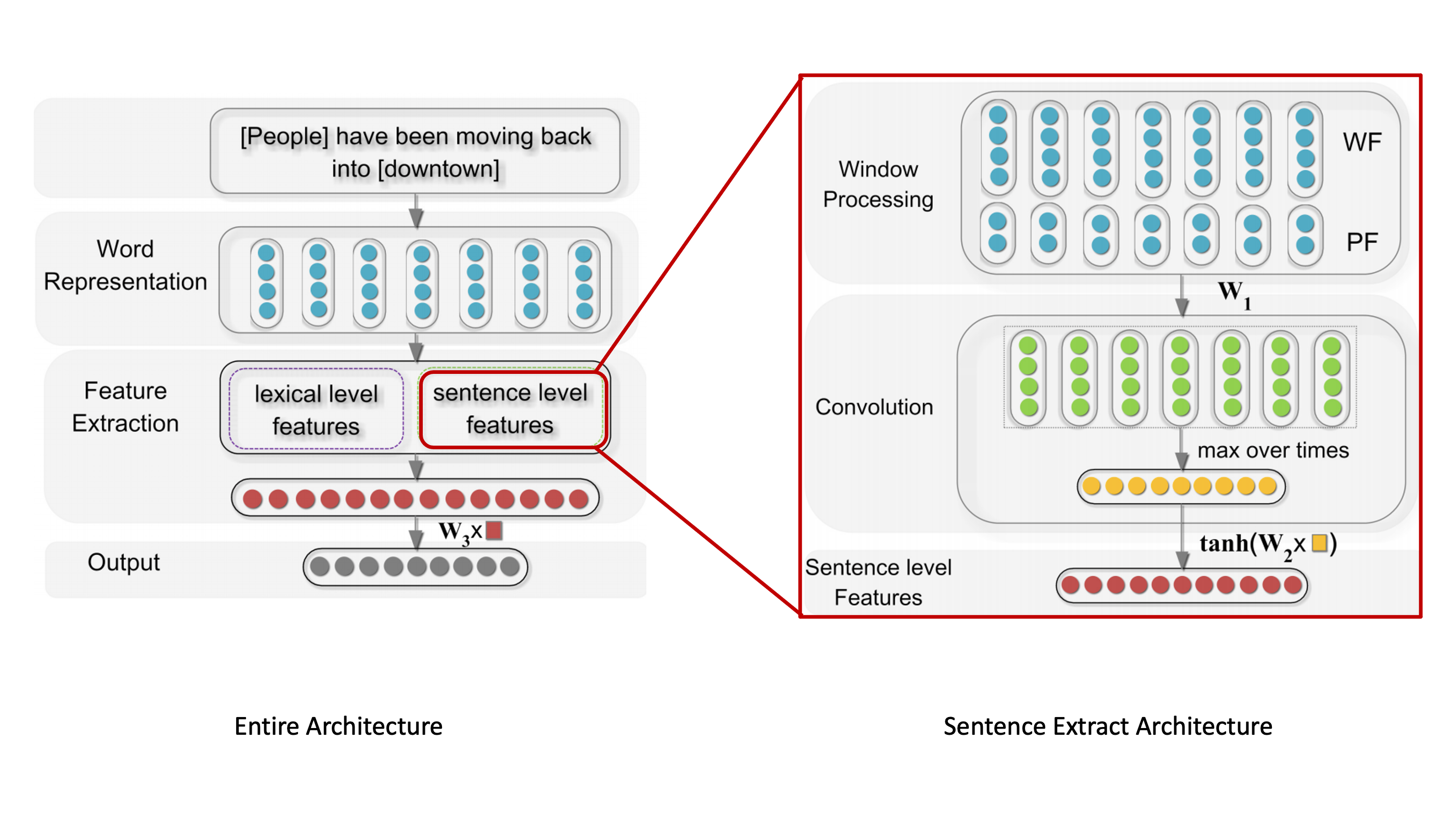
Sentence Level Feature Extracing은 총 3단계로 이루어져있다.
- Word Feature + Position Feature
- Conv + Max pooling
- Non-linearity(Activate Function)
Word Feature & Position Feature
각 단어의 문장 수준에서의 정보를 추출하는 첫번 째 단계이다. 여기서 추출할 정보는 2가지이다.
- 단어 주변 단어들은 무엇인가?
- 단어와 target 단어와의 거리는 얼마나 떨어져있는가?

이미 이전 단계에서 각 단어들은 밀집벡터(embedding vector)로 표현되어있고, window size는 3으로 했을 때의 Word Fearue(이하 WF)와 Position Feature(PF)는 이렇게 된다.

조금더 자세하게 살펴보자
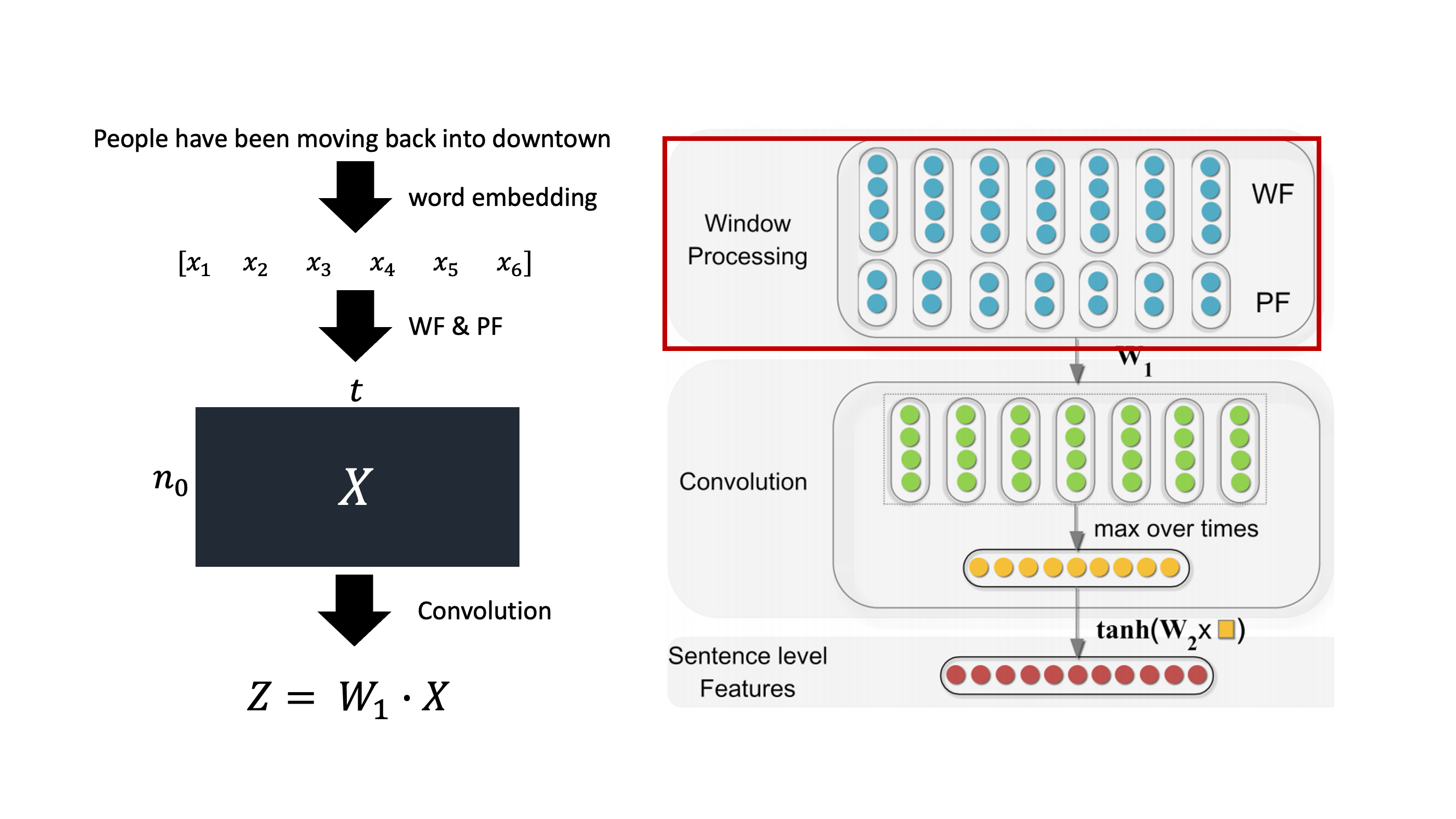
$n\ :\ Embedding\ dimension$
$w\ :\ window\ size$
$x \subseteq \mathbb{R}^{n} $
$t\ : $토큰(단어) 수
$n_{0}\ :\ w \times n\ +\ len(PF)$
$n_{1} : hidden\ size\ of\ next\ layer$
$W_{1} : n_{1} \times n_{0}$
$n_{0}$이 의미하는 것은 각 단어(토큰)에 대해서 WF와 PF를 concat한 길이를 의미한다. 즉 $X$가 의미하는 것은 각 토큰에 대해 WF+PF들을 구한 행렬을 의미한다.
WF = $w \times n$
PF = 2
그런데 논문에서는
where $n_0 = w \times n$, $n$ (a hyperparameter) is the dimension of feature vector, and $t$ is the token number of the input sentence
PF 길이를 안더해주는데 좀 건방지지만 아마 논문에서 잘못쓴게….아닌가싶다(아님랄로).
Convolution
흔히 아는 Conv filter로 특징 추출을 하는것이 아니라 그냥 행렬 곱을 해준것 밖에 없는데 왜 Convolution이라고 붙였는지 모르겠다.
$Z = W_1 \cdot X$
이 $Z$가 Convolution을 한 결과다. 그리고 row 별로 max pooling을 해준다.
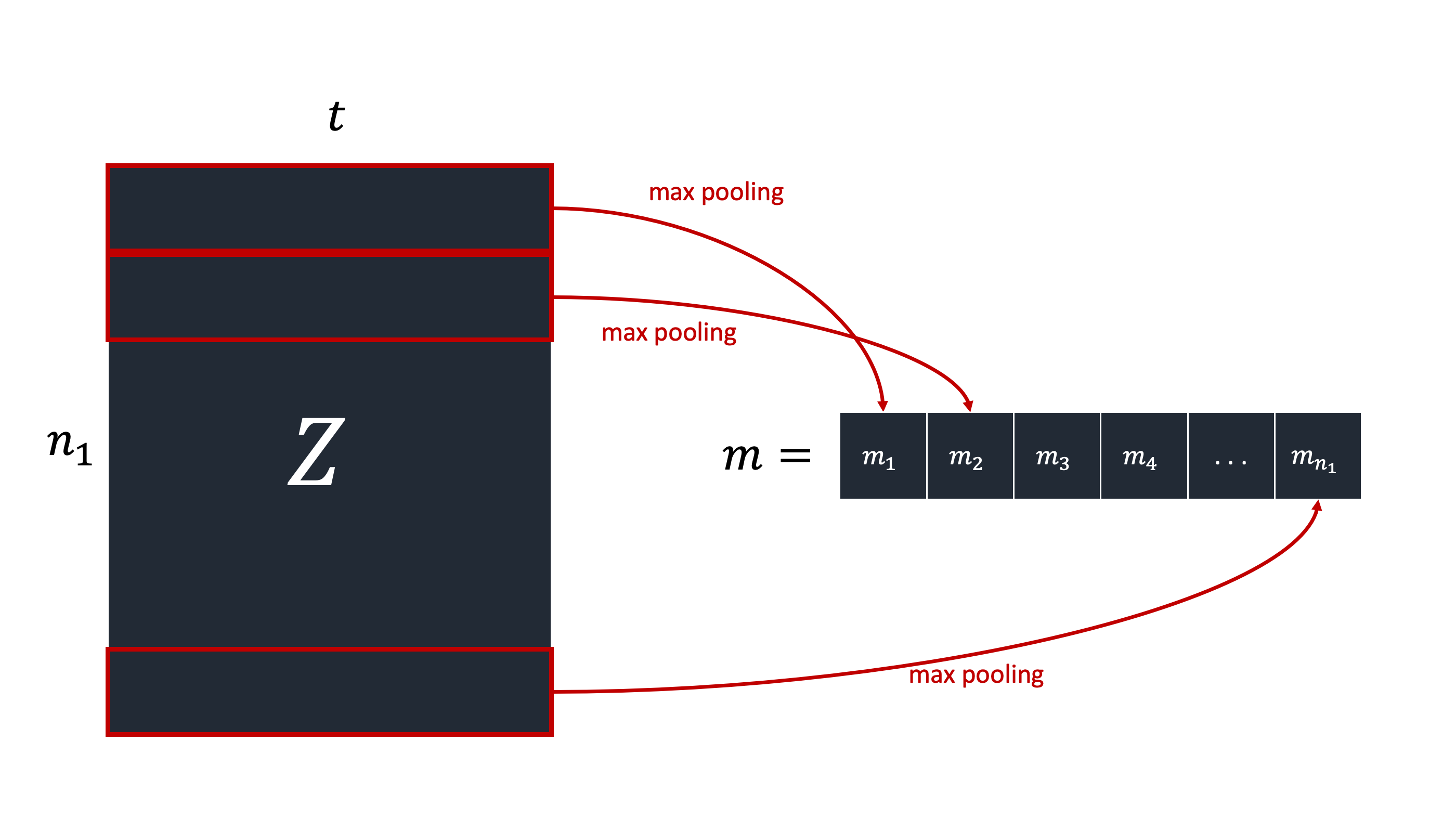
Non-linearity
마지막으로 max pooling의 결과인 $m$벡터와 $W_2$를 내적해준다. $W_2$의 사이즈는 $n_{2} \times n_{1}$이다. 그리고 위 그림에서 나왔듯이 하이퍼볼릭 탄젠트 함수를 이용해 벡터를 [-1, 1]사이 값으로 만들어준다.
Output
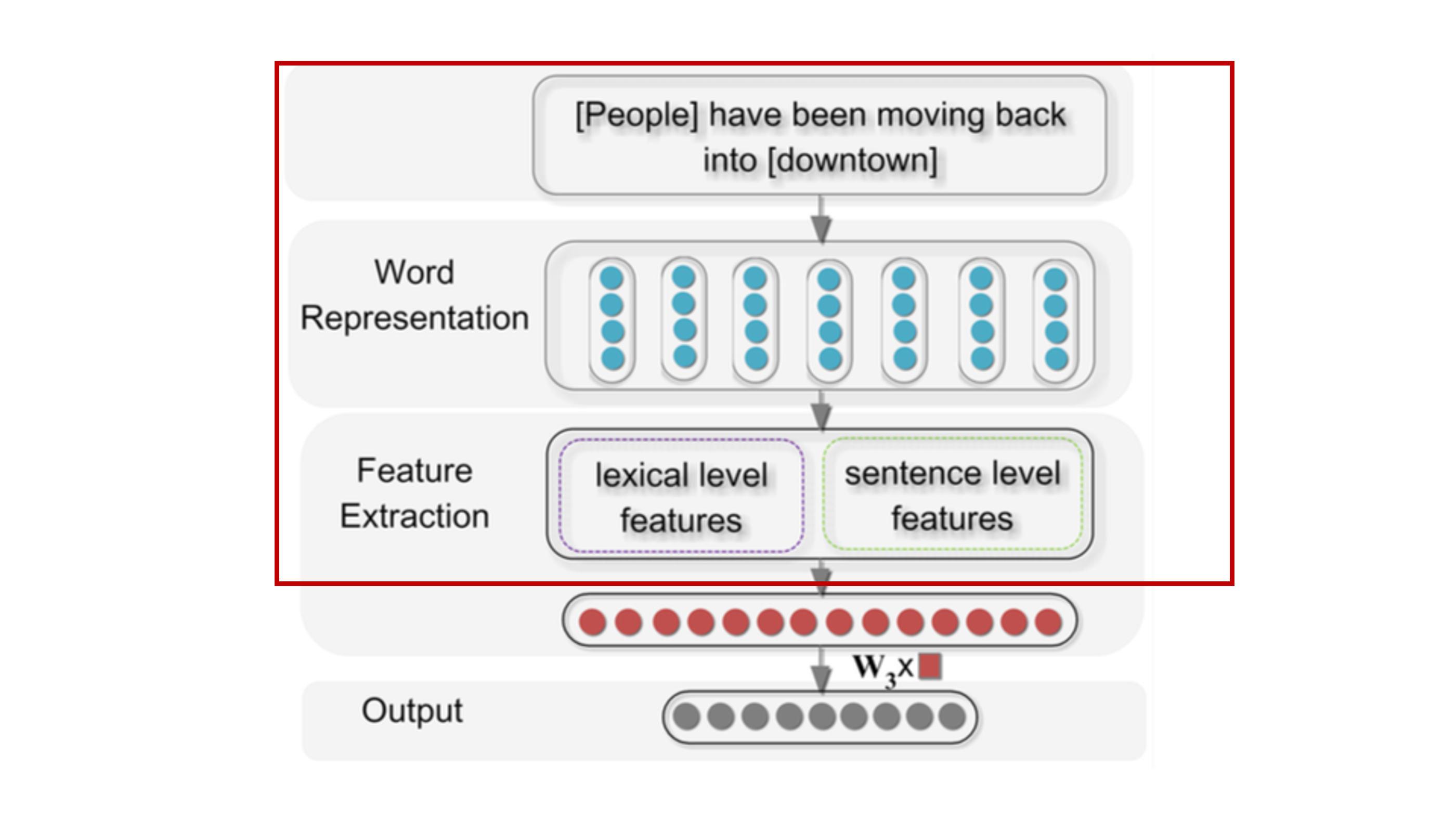
여기까지가 빨간 네모박스 까지 진행한것이다. 그 다음 단계는 정말 쉽다.
- $f$ = concat(lexical feature, sentence feature)
- $O = W_3 \times f$
$O$의 길이는 relation의 종류의 수(others 포함)가된다. 여기까지가 FeedForward Propagation이다.
Back Propagation
정말 간단하다. output $O$에 softmax를 취한 뒤 $Log likelihood$를 취한것이 Loss함수다.
\[p(i|x, \theta) = \frac{e^{o_{i}}}{\sum_{k=1}^{n_{4}}e^{o_{k}}}\] \[L(\theta) = log\ p(y|x, \theta)\]
파라미터 업데이트는
\[\theta \leftarrow \theta + \lambda\frac{\partial log p(y|x, \theta)}{\partial \theta}\]
실험(pass)
실험결과인데 대단한 내용도없고, 재밌는 실험도 없고 귀찮기도 해서 pass 할 예정이다. 대충 요약하면 다른 기존의 모델들과 비교(f1 scorer기준), 최적의 하이퍼파라미터, 그리고 추출한 특징(lexical, sentence)에 대해서 간략하게 소개하는 내용이다.