지난 포스팅 에서 dropout 정규화 + GPU를 포함하게끔 리팩토링 해보았다.
MNIST DataSet Load
import gzip
import os
import sys
import struct
import numpy as np
def read_image(fi):
magic, n, rows, columns = struct.unpack(">IIII", fi.read(16))
assert magic == 0x00000803
assert rows == 28
assert columns == 28
rawbuffer = fi.read()
assert len(rawbuffer) == n * rows * columns
rawdata = np.frombuffer(rawbuffer, dtype='>u1', count=n*rows*columns)
return rawdata.reshape(n, rows, columns).astype(np.float32) / 255.0
def read_label(fi):
magic, n = struct.unpack(">II", fi.read(8))
assert magic == 0x00000801
rawbuffer = fi.read()
assert len(rawbuffer) == n
return np.frombuffer(rawbuffer, dtype='>u1', count=n)
if __name__ == '__main__':
os.system('wget -N http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz')
os.system('wget -N http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz')
os.system('wget -N http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz')
os.system('wget -N http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz')
np.savez_compressed(
'mnist',
train_x=read_image(gzip.open('train-images-idx3-ubyte.gz', 'rb')),
train_y=read_label(gzip.open('train-labels-idx1-ubyte.gz', 'rb')),
test_x=read_image(gzip.open('t10k-images-idx3-ubyte.gz', 'rb')),
test_y=read_label(gzip.open('t10k-labels-idx1-ubyte.gz', 'rb'))
)
# GPU 설정 확인
print(torch.cuda.is_available())
dev = torch.device(
"cuda") if torch.cuda.is_available() else torch.device("cpu")
True
data = np.load('mnist.npz')
x_train = data['train_x']
y_train = data['train_y']
x_test = data['test_x']
y_test = data['test_y']
# x_train.shaep : (60000, 28, 28) -> (60000, 784)
# x_test.shape : (10000, 28, 28) -> (10000, 784)
x_train = x_train.reshape((60000, 784))
x_test = x_test.reshape((10000, 784))
# numpy to troch
import torch
x_train, y_train, x_test, y_test = map(
torch.tensor, (x_train, y_train, x_test, y_test)
)
# y를 long으로 바꾸지 않으면 index에러같은게 떠서 바꿨습니다.
y_train = y_train.long()
y_test = y_test.long()
validation set
하이퍼 파라미터 튜닝을 위한 validation set을 train 에서 분리
# split data -> train, valid, test
from sklearn.model_selection import train_test_split
x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train,
test_size = 1/6, stratify = y_train,
random_state = 1)
print('x_train :', x_train.shape)
print('y_train :', y_train.shape)
print('x_valid :', x_valid.shape)
print('y_valid :', y_valid.shape)
print('x_test :', x_test.shape)
print('y_test :', y_test.shape)
x_train : torch.Size([50000, 784])
y_train : torch.Size([50000])
x_valid : torch.Size([10000, 784])
y_valid : torch.Size([10000])
x_test : torch.Size([10000, 784])
y_test : torch.Size([10000])
Datset GPU apply
# Data to GPU
x_train, y_train = x_train.to(dev), y_train.to(dev)
x_valid, y_valid = x_valid.to(dev), y_valid.to(dev)
x_test, y_test = x_test.to(dev), y_test.to(dev)
DNN 구현
리팩토링
dropout을 위해
MyModule에nn.Dropout을 추가output layer를 제외한 나머지 layer들에
dropout설정
model에 GPU 설정
import torch.nn.functional as F
from torch import nn
from torch import optim
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import time
# Cross entropy loss func
loss_func = F.cross_entropy
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
class MyModule(nn.Module):
def __init__(self, layer = 1, dp = None):
super().__init__()
self.max_layer = 512
self.relu = nn.ReLU()
self.log_softmax = nn.LogSoftmax()
self.linears = nn.ModuleList()
# add regularzation dropout
self.dropout = nn.Dropout(p = dp)
'''
layer = 1 : 784 x 10
layer = 2 : 784 x 512 x 10
layer = 3 : 784 x 512 x 256 x 10
layer = 4 : 784 x 512 x 256 x 126 x 10
layer = 5 : 784 x 512 x 256 x 126 x 64 x 10
'''
if layer > 1 :
self.linears.append(nn.Linear(784, self.max_layer))
for i in range(2, layer) :
self.linears.append(nn.Linear(self.max_layer, self.max_layer // 2))
self.max_layer //= 2
self.linears.append(nn.Linear(self.max_layer, 10))
else :
self.linears.append(nn.Linear(784, 10))
def forward(self, x):
for linear in self.linears[:-1] :
# apply dropout
x = linear(x)
if dp is not None :
x = self.dropout(x)
x = self.relu(x)
# output layer
x = self.log_softmax(self.linears[-1](x))
return x
# model, optim 설정
def get_model(layer = 1, lr = 0.01, dp = 0.5):
model = MyModule(layer = layer, dp = dp)
return model.to(dev), optim.SGD(model.parameters(), lr=lr)
'''
fit의 가독성을 위해 Dataset, DataLoader 모듈을 이용해
batch_size 크기씩 뽑아올 수 있게 iterator 객체로 만들어 준다.
'''
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
'''
test 데이터와, train 데이터일때의 구별을 하기위해 opt = None으로 설정
test 데이터에서 쓸데없이 parameter 업데이트가 되지 않도록 하기 위해서
'''
def loss_batch(model, loss_func, xb, yb, opt=None):
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
return loss.item()
'''
fit 함수
x_train, y_train으로 학습을 끝낸 후
train, test의 정확도를 출력
'''
def fit(epochs, model, loss_func, opt, train_dl, test_dl):
start = time.time()
train_loss = []
model.train()
for epoch in range(epochs):
for xb, yb in train_dl:
loss = loss_batch(model, loss_func, xb, yb, opt)
train_loss.append(loss)
if (epoch + 1) % 50 == 0:
print('{} epoch is done'.format(epoch + 1))
print("cost time :", time.time() - start)
return train_loss
batch_size = 1024
epochs = 400
lr = 0.05
dp = 0.5
# Dataset 정리
train_ds = TensorDataset(x_train, y_train)
valid_ds = TensorDataset(x_valid, y_valid)
train_dl, valid_dl = get_data(train_ds, valid_ds, batch_size)
no_dropout_train_accuracy = []
no_dropout_valid_accuracy = []
no_dropout_test_accuracy = []
dropout_train_accuracy = []
dropout_valid_accuracy = []
dropout_test_accuracy = []
# dropout을 쓰고 안썼을 때의 성능 출력을 위한 함수
def total_acc() :
model.train()
train_acc = accuracy(model(x_train), y_train)
valid_acc = accuracy(model(x_valid), y_valid)
test_acc = accuracy(model(x_test), y_test)
no_dropout_train_accuracy.append(train_acc)
no_dropout_valid_accuracy.append(valid_acc)
no_dropout_test_accuracy.append(test_acc)
print('no dropout train accuracy : ', round(train_acc.item(), 4))
print('no dropout valid accuracy : ', round(valid_acc.item(), 4))
print('no dropout test accuracy : ', round(test_acc.item(), 4))
print('-'*60)
model.eval()
train_acc = accuracy(model(x_train), y_train)
valid_acc = accuracy(model(x_valid), y_valid)
test_acc = accuracy(model(x_test), y_test)
dropout_train_accuracy.append(train_acc)
dropout_valid_accuracy.append(valid_acc)
dropout_test_accuracy.append(test_acc)
print('dropout train accuracy : ', round(train_acc.item(), 4))
print('dropout valid accuracy : ', round(valid_acc.item(), 4))
print('dropout test accuracy : ', round(test_acc.item(), 4))
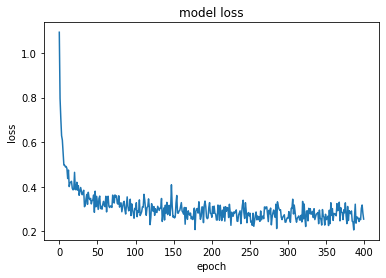
Layer : 1
model, opt = get_model(layer = 1, lr = lr, dp = dp)
train_loss = fit(epochs, model, loss_func, opt, train_dl, valid_dl)
50 epoch is done
100 epoch is done
150 epoch is done
200 epoch is done
250 epoch is done
300 epoch is done
350 epoch is done
400 epoch is done
cost time : 131.54349088668823
total_acc()
no dropout train accuracy : 0.9252
no dropout valid accuracy : 0.9253
no dropout test accuracy : 0.9224
------------------------------------------------------------
dropout train accuracy : 0.9252
dropout valid accuracy : 0.9253
dropout test accuracy : 0.9224
plt.plot(train_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
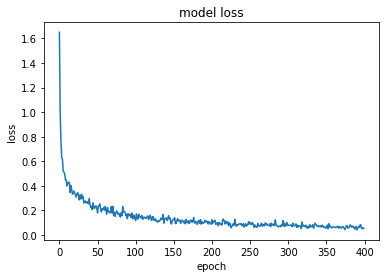
Layer : 2
model, opt = get_model(layer = 2, lr = lr, dp = dp)
train_loss = fit(epochs, model, loss_func, opt, train_dl, valid_dl)
50 epoch is done
100 epoch is done
150 epoch is done
200 epoch is done
250 epoch is done
300 epoch is done
350 epoch is done
400 epoch is done
cost time : 147.71701765060425
total_acc()
no dropout train accuracy : 0.9825
no dropout valid accuracy : 0.973
no dropout test accuracy : 0.9734
------------------------------------------------------------
dropout train accuracy : 0.9897
dropout valid accuracy : 0.9789
dropout test accuracy : 0.9795
plt.plot(train_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
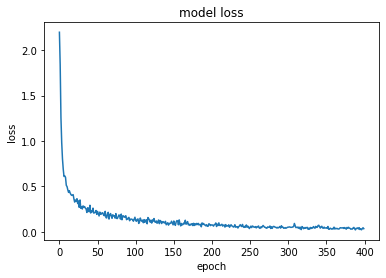
Layer : 3
model, opt = get_model(layer = 3, lr = lr, dp = dp)
train_loss = fit(epochs, model, loss_func, opt, train_dl, valid_dl)
50 epoch is done
100 epoch is done
150 epoch is done
200 epoch is done
250 epoch is done
300 epoch is done
350 epoch is done
400 epoch is done
cost time : 148.58326697349548
total_acc()
no dropout train accuracy : 0.989
no dropout valid accuracy : 0.9751
no dropout test accuracy : 0.9711
------------------------------------------------------------
dropout train accuracy : 0.9976
dropout valid accuracy : 0.9821
dropout test accuracy : 0.9821
plt.plot(train_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
Layer : 4
model, opt = get_model(layer = 4, lr = lr, dp = dp)
train_loss = fit(epochs, model, loss_func, opt, train_dl, valid_dl)
50 epoch is done
100 epoch is done
150 epoch is done
200 epoch is done
250 epoch is done
300 epoch is done
350 epoch is done
400 epoch is done
cost time : 151.22508549690247
total_acc()
no dropout train accuracy : 0.9929
no dropout valid accuracy : 0.9707
no dropout test accuracy : 0.9698
------------------------------------------------------------
dropout train accuracy : 0.9997
dropout valid accuracy : 0.9827
dropout test accuracy : 0.9822
plt.plot(train_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
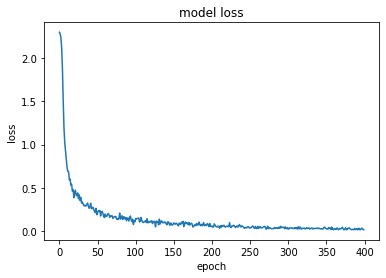
Layer : 5
model, opt = get_model(layer = 5, lr = lr)
train_loss = fit(epochs, model, loss_func, opt, train_dl, valid_dl)
50 epoch is done
100 epoch is done
150 epoch is done
200 epoch is done
250 epoch is done
300 epoch is done
350 epoch is done
400 epoch is done
cost time : 153.1449098587036
total_acc()
no dropout train accuracy : 0.9938
no dropout valid accuracy : 0.9691
no dropout test accuracy : 0.969
------------------------------------------------------------
dropout train accuracy : 0.9999
dropout valid accuracy : 0.9808
dropout test accuracy : 0.9794
plt.plot(train_loss)
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
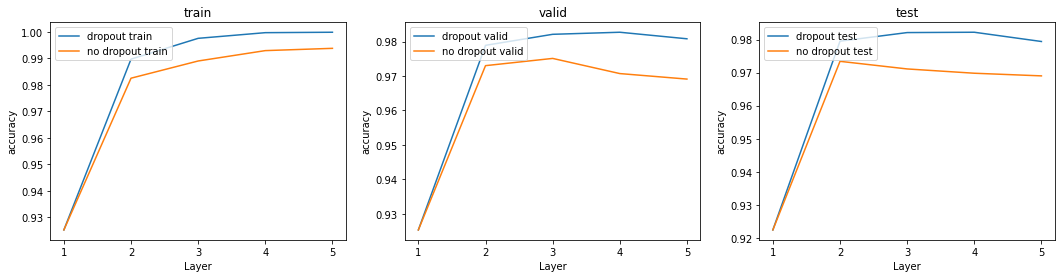
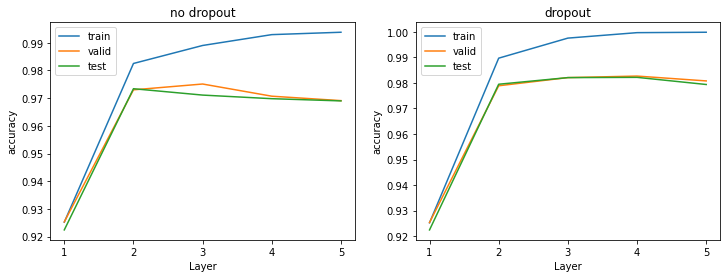
종합적인 비교
GPU
GPU 사용으로 속도가 미친듯이 빨라졌다.
[no GPU in layer 5]cost time : 633.75
[GPU in layer 5]cost time : 153.14
이속도면 1000 epoch 돌려도 GPU가 더 빠를듯하다. 최적의 hyperparmeter 를 찾다기 보단, dropout을 사용했을 때의 성능 변화를 보기위해 튜닝을 안해봤지만 이 속도면 튜닝을 마음껏 해도 될듯.
overfitting
test data에서 확실하게 성능이 좋아진것을 확인할 수 있었다.
dropout = 0.5정도로 해서 layer가 많아질 수록 미세하게 test data의 성능이 떨어지긴 하지만 큰 의미있는 변화를 확인할 수 있음
fig, axes = plt.subplots(1, 2)
fig.set_size_inches(12, 4)
label = [1, 2, 3, 4, 5]
graphs = [(no_dropout_train_accuracy, no_dropout_valid_accuracy, no_dropout_test_accuracy),
(dropout_train_accuracy, dropout_valid_accuracy, dropout_test_accuracy)]
titles = ['no dropout', 'dropout']
for ax, title_, graph in zip(axes, titles, graphs) :
ax.plot(label, graph[0])
ax.plot(label, graph[1])
ax.plot(label, graph[2])
ax.set_xticks(label)
ax.legend(['train', 'valid', 'test'], loc='upper left')
ax.set(xlabel = 'Layer', ylabel = 'accuracy', title = title_)
fig, axes = plt.subplots(1, 3)
fig.set_size_inches(18, 4)
label = [1, 2, 3, 4, 5]
titles = ['train', 'valid', 'test']
graphs = [(no_dropout_train_accuracy, dropout_train_accuracy),
(no_dropout_valid_accuracy, dropout_valid_accuracy),
(no_dropout_test_accuracy, dropout_test_accuracy),]
for ax, title_, graph in zip(axes, titles, graphs) :
ax.plot(label, graph[1])
ax.plot(label, graph[0])
ax.set(xlabel = 'Layer', ylabel = 'accuracy', title = title_)
ax.set_xticks(label)
ax.legend(['dropout {}'.format(title_), 'no dropout {}'.format(title_)], loc='upper left')