import datetime
def solution(lines):
time_interval = []
answer = 0
for line in lines :
date, end_time, take_time = line.split(' ')
end = datetime.datetime.strptime(date+' '+end_time, '%Y-%m-%d %H:%M:%S.%f')
start = end - datetime.timedelta(seconds = float(take_time[:-1])-0.001)
time_interval.append((start.timestamp(), end.timestamp()+0.999))
time_interval.sort()
for time_ in [log for start_to_end in time_interval for log in start_to_end]:
cnt = 0
for start, end in time_interval:
if start <= time_ <= end :
cnt += 1
answer = max(answer, cnt)
return answer
datetime.datetime.strptime()
str 타입의 시간형식을 datetime 형식의 시간으로 바꾸어 시간차를 구할 수 있게 해준다.
a = datetime.datetime.strptime('2016-09-15 22:57:57.421', '%Y-%m-%d %H:%M:%S.%f')
b = datetime.datetime.strptime('2016-09-15 20:59:57.421', '%Y-%m-%d %H:%M:%S.%f')
print(a-b)
1:58:00
풀이
log 시작 시간
예를 들어, 로그 문자열
2016-09-15 03:10:33.020 0.011s은 2016년 9월 15일 오전 3시 10분 33.010초부터 2016년 9월 15일 오전 3시 10분 33.020초까지 0.011초 동안 처리된 요청을 의미한다. (처리시간은 시작시간과 끝시간을 포함)
지문에 나와있는 그대로 가져왔다. 즉 시작시간은 처리시간에 0.001초를 뺀 시간을 구해주어야 한다.
시작시간 = 끝난시간 - 처리시간 - 0.001s
같이 처리되는 로그?
문제에서 주어진 초당 최대 처리량의 정의
초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리초)간 처리하는 요청의 최대 개수를 의미한다.
무슨말이냐 하면 한 로그의 처리가 끝나고 1초안에 들어온 로그는 같이 처리한 로그로 본다는 말이다.
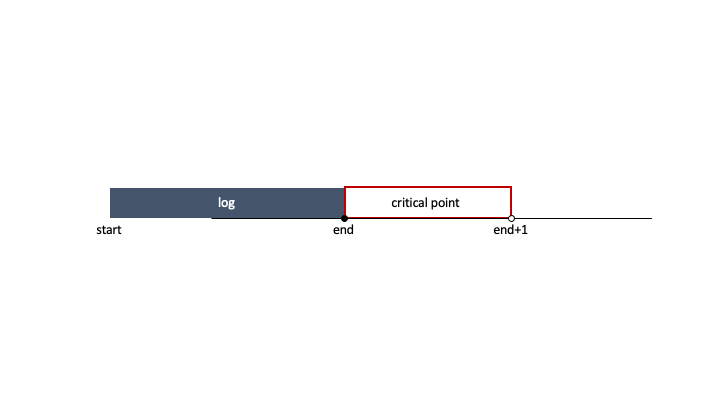
이 critical point의 범위 내에 다른 로그가 있으면 그놈은 같이 처리된 트래픽으로 센다는 말이다. 그리고 최소 0.001단위까지 셀 수 있다.
check point
1초동안에 몇개의 로그가 동시에 처리되는지 세기위해 첫 로그가 들어온 순간부터 0.001초씩 필터를 옮겨가며 세면 시간초과에 걸린다. 그럴 필요없이 각 로그의 시작점 또는 임계점의 끝부분 이 다른 로그들과 걸쳐지는 지점만 세주면 된다.
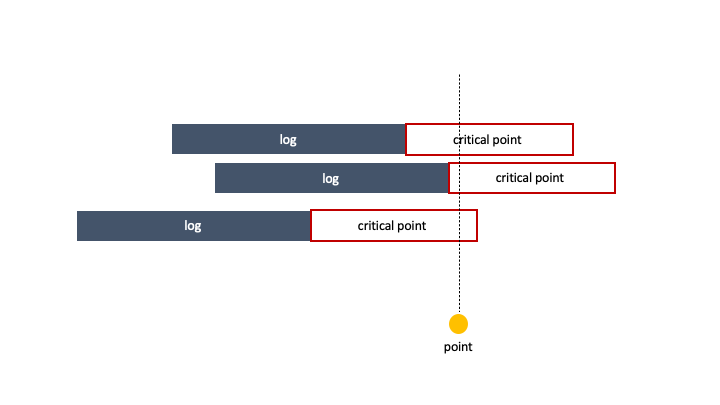
end + 0.999를 해주었기 때문에(같이 처리되는 부분을 포함시켰다는 말) 그렇다. 이해안되면 걍 공감해라.
start_to_end
for line in lines :
date, end_time, take_time = line.split(' ')
end = datetime.datetime.strptime(date+' '+end_time, '%Y-%m-%d %H:%M:%S.%f')
start = end - datetime.timedelta(seconds = float(take_time[:-1])-0.001)
time_interval.append((start.timestamp(), end.timestamp()+0.999))
time_interval.sort()
위에 설명한대로 (start, end+0.999)를 time_interval에 저장해주고 start를 기준으로 정렬시킨다.
count
time_interval 에 저장된 start, end 순으로 얘네가 몇개랑 겹치는지 세준다.
for time_ in [log for start_to_end in time_interval for log in start_to_end]:
cnt = 0
for start, end in time_interval:
if start <= time_ <= end :
cnt += 1
answer = max(answer, cnt)

import datetime
def solution(lines):
time_interval = []
answer = 0
for line in lines :
date, end_time, take_time = line.split(' ')
end = datetime.datetime.strptime(date+' '+end_time, '%Y-%m-%d %H:%M:%S.%f')
start = end - datetime.timedelta(seconds = float(take_time[:-1])-0.001)
time_interval.append((start.timestamp(), end.timestamp()+0.999))
time_interval.sort()
for time_ in [log for start_to_end in time_interval for log in start_to_end]:
cnt = 0
for start, end in time_interval:
if start <= time_ <= end :
cnt += 1
answer = max(answer, cnt)
return answer