지난 포스트에서 CapsNet의 동작에대해 살펴보았는데 이번 포스트에선 CapsNet이 얼마나 일을 잘하는가에대한 부분을 살펴보도록 하겠다.
Reference
- Dynamic Routing Between Capsules 원본 논문
- 시카고 대학 Dr Charles martin 의 유투브 동영상
- Hands-on Machine Learning 저자 Aurélien Géron 의 유투브 동영상
- 논문 저자 중 한명인 Sara Sabour 의 유투브 동영상
- jayhey’s Blog
- CapsNet 구현코드1 Pytorch 구현
- CapsNet 구현코드2 Pytorch 구현
Capsule Network 실험 결과
논문에서 CapsNet에 대해 강조한 부분은 2가지다.
- CapsNet은 feature 간의 spatial relationship을 고려한 예측을 한다.
- CapsNet은 highly overlapping object recognition에 강하다
- 논문에서는 “We demonstrate that our dynamic routing mechanism is an effective way to implement the “explaining away” that is needed for segmenting highly overlapping objects.” 이렇게 주장한다.
2번째 강조한 내용인 highly overlapping objects에 강하다 라고 말하는데 사실 이부분의 원리를 이해못했다. explaining away로 인해서 겹쳐진 이미지도 잘 구별한다는데…하여튼 나는 이부분이 잘 이해가 안됬음.
Reconstructions

- $l$ : label
- $p$ : predict
- $r$ : reconstruction
이 사진은 CapsNet이 얼마나 reconstruction을 잘하는지를 보여준다. 그런데 읽어보면 알겠지만 마지막 2개의 example은 잘 못한 case인데, 이부분도 사실 이해가 잘 안되는데 아마도 test단계에서 같은 test input에 대해 5번째 예시는 label로 reconstruction한 예시를 보여주는 것이고 6번째는 predict를 reconstruction한 예시를 보여주는 것으로 추정된다. 꽤나 정확한 reconstruction 성능을 보여준다.
ConvNet VS CapsNet
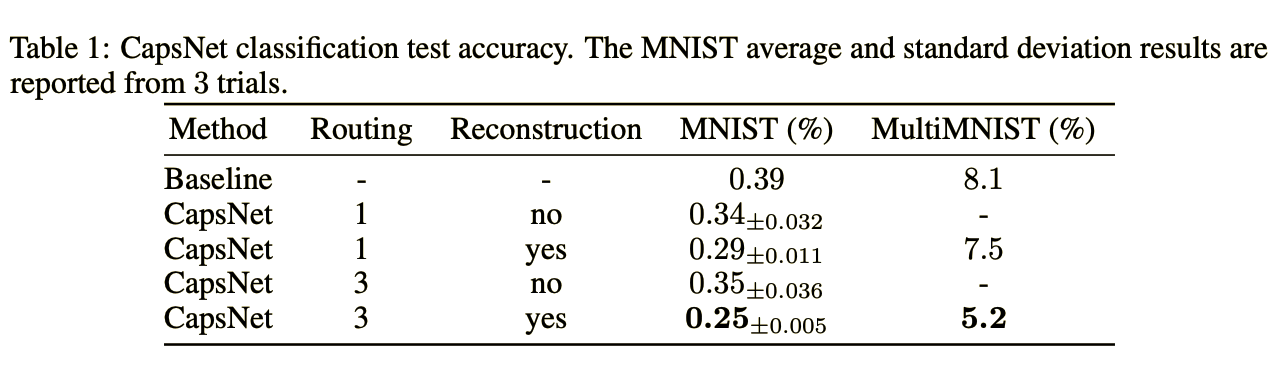
이 예시는 CNN과 CapsNet의 성능 차이를 보여주는 지표로, 비교에 사용된 CNN의 스펙은 이렇다.
Channel : [256, 256, 128]
each kernel : 5x5
each stride : 1
FC layer : [328(ReLU), 192(ReLU), 10(softmax)]
위에서부터 보면
- CNN 모델 정확도 : 0.9961
- CapsNet, routing : 1, Reconstruction : None 정확도 : 0.9966
- CapsNet, routing : 1, Reconstruction : yes 정확도 : 0.9971
- CapsNet, routing : 3, Reconstruction : None 정확도 : 0.9965
- CapsNet, routing : 1, Reconstruction : None 정확도 : 0.9975
핵심은 Reconstruction Loss를 추가했냐 안했냐에 따라 매우 큰 효과를 보는 듯 하다. 그리고 추가로 learning parameter에 관한 비교도 있는데
CNN parameter : 35.4M
CapsNet parameter : 6.8M + 1.4M(Reconstruction Parameters)
파라미터 개수에서 월등하게 우월한 성능을 보여준다. 즉 CNN보다 정확도도 높으면서 모델또한 가볍다
Means of Instantion parameter
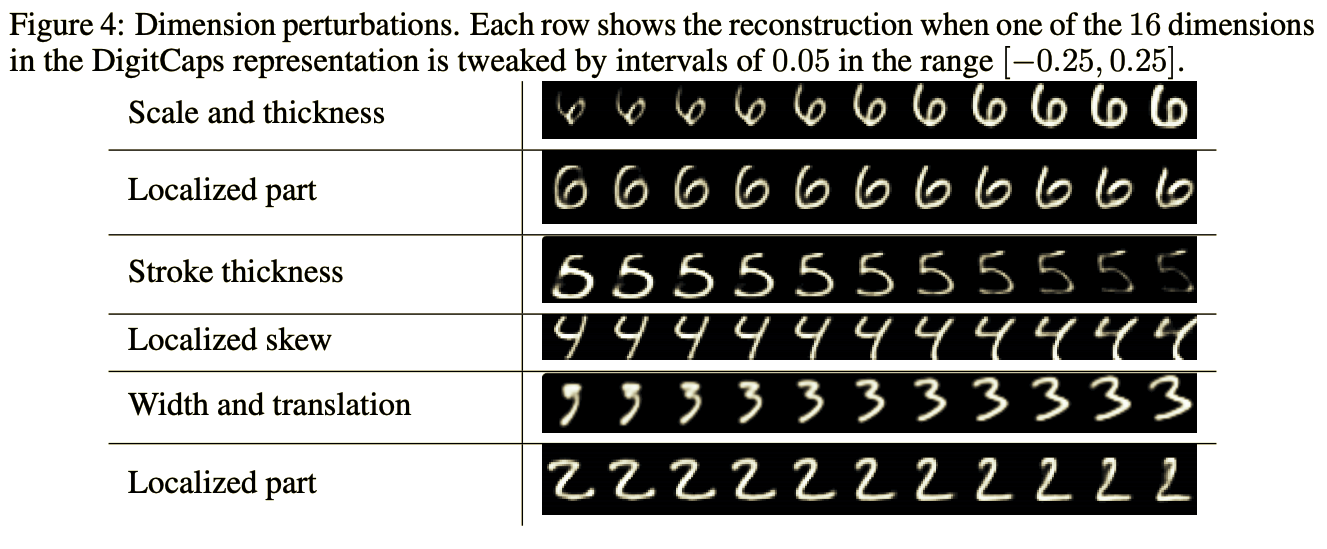
이 이미지는 digitCaps의 Instantion parameter 값 중 하나를 0.05단위로 [-0.25, -0.20, …, 0.20, 0.25]씩 반복문을 돌려서 reconstruction을 확인한 결과인데, Instantion parameter값을 하나씩 바꿀 때 마다 reconstruction도 조금씩 변한다는 것을 보여주기위해 보여주는 결과이다. 왼쪽의 thickness, skew 이런것들은 연구진들이 관찰한 결과를 써놓은것뿐이니(“이걸바꾸니 두꺼워지네? 이건 thickness에 영향을 주는 Instantion parameter인가보다” 이런식으로) 신경 쓸 필요없고 중요한 것은 각 Instantion parameter들이 entity의 특정 분야를 담당하고 있다 라는 사실을 주목해주면 된다.
On affNIST dataset
이 실험은 좀 놀랄만한 실험 결과였는데 affNIST라고 기존의 MNIST보다 조금 더 큰 사이즈(40 x 40)에 MNIST 데이터에 Affine Transformation(rotate, shift)이 가해진 손글씨 데이터이다.

affNIST example
그런데 여기서 재미있는 실험을 하는데 기존의 MNIST 데이터에 padding을 해서 40 x 40 크기로 맞춰놓고 MNIST데이터로만 훈련을 시킨 뒤에 한번도 본적 없는 affNIST 데이터로 성능을 테스트 해본것이다. 그 결과는
CNN
- train score : 99.22%
- test score : 66%
CapsNet
- train score : 99.23%
- test score : 79%
test에서 무려 13%나 차이가 난것을 확인할 수 있다. translation equvariance로 spatial relationship을 고려한 모델의 성능을 확실하게 보여준 예시가 아닌가 생각한다.
On MultiMNIST dataset
논문저자중 한명인 Sara Sabour의 설명 동영상인데 진짜 발음이 이빨 다 뽑힌것마냥 공기가 줄줄샌다. 듣다가 빡쳐서 포기했는데 원리에 대해서 알고싶은 사람들은 들어보는것도 좋을듯 하다. 대충 특정 feature가 support 하는 capsule이 없으면 예측을 안하기 때문에 정확하게 예측을한다라는 내용을 설명해준다.
이 실험은 위에서 언급한 CapsNet이 explaining away를 이용해 겹쳐진 object도 잘 구별 해낸다 라는것을 보여주기위한 실험이다. MultiMNIST dataset은 연구진들이 직접 만든 데이터로 MNIST data의 서로다른 2개의 숫자를 최대 80%이상 겹쳐지도록 만든 데이터이다.

R : reconstruction
L : Label
하얀 숫자이미지가 원본 이미지이고 빨강, 초록 숫자 이미지가 reconstruct한것을 합친 이미지이다.
1~4 열까지는 분할을 잘한 case를 보여준다. 정말 어떻게 분할한건지 특히 3번째 결과물은 놀라울 따름이다.
그리고 5~6열의 예시는 2개의 숫자 중 한 숫자는 input에 속해있는 숫자를 그리고 나머지 한 숫자는 input or prediction에없는 임의의 숫자를 reconstruction하도록 시킨 예시이다. 아래쪽의 5번째 예시를 보면 input으로 <1, 8>이 겹쳐진 이미지를 주고 <0, 8>을 reconstruction 하게끔 한 이미지인데, 8은 input에 있으니 잘 reconstruction하는데 input or predict에 없는 0은 전혀 reconstruction을 안하는 모습을 보여준다.
그리고 7~8열의 예시는 같은 input에 대해서 input 숫자 2개를 reconstruction 한 결과와 (“P”가 붙어있는) prediction 숫자 2개를 reconstruction 한 결과를 보여주는 예시이다.
Capsule Network 단점
우선 CapsNet의 단점은 3가지로 들 수 있다.
- Routing Algorithm으로 인해 학습 속도가 느리다
- 실제 RGB채널의 Image에 대해서(예를들면 CIFAR10) 월등하게 좋은 성적을 거두지 못한다.
- 큰 사이즈의 이미지에대해서도 잘 동작하는지 그건 모른다(?)
1번은 지금 나도 코드를 해석해서 이전 3D MNIST에 적용시켜보고 결과를 보려고 해석하는 중이라 설명을 못하고, 3번같은 경우도 당연히 1번을 해결못했으니 아직 못하고 2번에대해서 말하도록 하겠다.
CapsNet의 문제점이 Image안의 모든것을(배경, 주변에 잡것들) capsule화 하려고 하기 때문에 오히려 예측에 방해가 된다라고 한다. 그 이유가 인간의 시야 현상에서 발생하는 Crowing 효과가 CapsNet에서도 발생해서 그렇다고 하는데 직접 해본것이 아니라서 이해가 잘 안된다.

crowing 효과가 뭐냐하면 위의 이미지에서 x에 초점을두고 오른쪽의 깜빡거리는 문자열들을 인신하는 문제인데. (왼쪽에 집중을 하면서) 오른쪽에 간단한 하나짜리 문자가 나오면 잘 인식하지만 복잡한 문자열이 나오면 인식하기 힘든 현상인데 이게 무슨관계인지 잘 모르겠다.
One drawback of Capsules which it shares with generative models is that it likes to account for everything in the image so it does better when it can model the clutter than when it just uses an additional “orphan” category in the dynamic routing. In CIFAR-10, the backgrounds are much too varied to model in a reasonable sized net which helps to account for the poorer performance.
논문에서는 CIFAR10 예측에 문제가 있어서 마지막 layer에 “해당사항없음”이라는 라벨까지 만들어도 보고 뭐 clutter(?) 도 해봤다 이런식으로 말했는데 이건 잘 모르겠다. 하여튼 여기까지 이론적인 부분에 대한 것이고 다음 포스팅은 실제로 코드로 만지작거리면서 궁금했던 부분들에대해 결과를 뽑아보는 포스팅을 하도록 하겠다.
첫 논문 리뷰 후기
논문 하나를 이해하기위해 거의 60시간은 쏟아 부은것같다. 같은동영상 이해될때 까지 최소 4번씩은보고 논문을 이해하기 위해 봤던 동영상을 이해하기위해 또 따로 자료를 찾아보고, 논문을 3번정독하고 너무많은 것들이 머리속에 들어와서 나는 알지만 이것을 풀어서 글로 쓰자니 너무 어려웠다. 하여튼 느낀점은 논문읽는거 엄청 어려울줄 알았는데 어렵긴하더라..근데 못할건 아니다. 하면서 영어실력도 느는것같고 글읽는 실력도 같이 느는것같아서 좀 괜찮은 공부법이라 느껴진다.