기존의 1차원 MNIST 데이터를 3차원 rgb 채널로 확장 시킨뒤 vgg network를 이용해 예측을 시도한다.
Prepare
지난포스트 에서 확장시킨 MNIST 데이터파일을 라벨별로 정리한 파일을 다운로드 해준다.
3dmnist/
|-- image/
| |-- test/
| | |-- 0/
| | |-- 1/
| | |-- 2/
. . .
| |-- train
| | |-- 0/
| | |-- 1/
| | |-- 2/
. . .
|-- model/
|-- runs/
디렉토리 구조는 root디렉토리 밑에 다운받은 image 폴더, 그리고 model, runs 를 만들어 준다.
model 폴더는 학습이 끝난 네트워크 모델이 저장될 폴더이고, runs는 tensorboard 데이터값을 위한 폴더이다.
import
필요한 모듈 및 함수들
import pandas as pd
import numpy as np
import time
import torch
from torch import nn
from torch import optim
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
# visualization
from tqdm import notebook
from matplotlib.legend_handler import HandlerLine2D
import matplotlib.pyplot as plt
%matplotlib inline
# tensorboard
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
import gc
'''
반복문을 사용할 때 cuda memory를 초기화 시켜주지 않으면 memory 용량이 부족한 경우가 생긴다.
'''
def clear_gpu() :
torch.cuda.empty_cache()
gc.collect()
Data Load
transform = transforms.Compose([transforms.ToTensor(),
# image normalization
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
데이터셋을 불러오며 augmentation 시켜주는 transform을 정의한다. Compose 함수 인자로 다른 여러가지 augmentation 방법이 있으니 관심있으면 참고하길 바란다.
transforms.ToTensor():28x28x3이미지를3x28x28로 transform 해줌
transforms.Normalize(): 이미지 벡터값을 [-1, 1] 사이 값을 가지도록 transform 해줌
train_dir = 'image/train' # 이미지의 최상위 디렉토리
test_dir = 'image/test' # 이미지의 최상위 디렉토리
train_ds = ImageFolder(train_dir, transform=transforms, target_transform=None)
valid_ds = ImageFolder(test_dir, transform=transforms, target_transform=None)
ImageFolder 를 이용해 train_ds, vaild_ds를 정의한다.
ImageFolder의 정확한 역할은 모르겠으나 아마도 이미지 폴더에 스트림을 연결시키는 역할을 하는것같다.
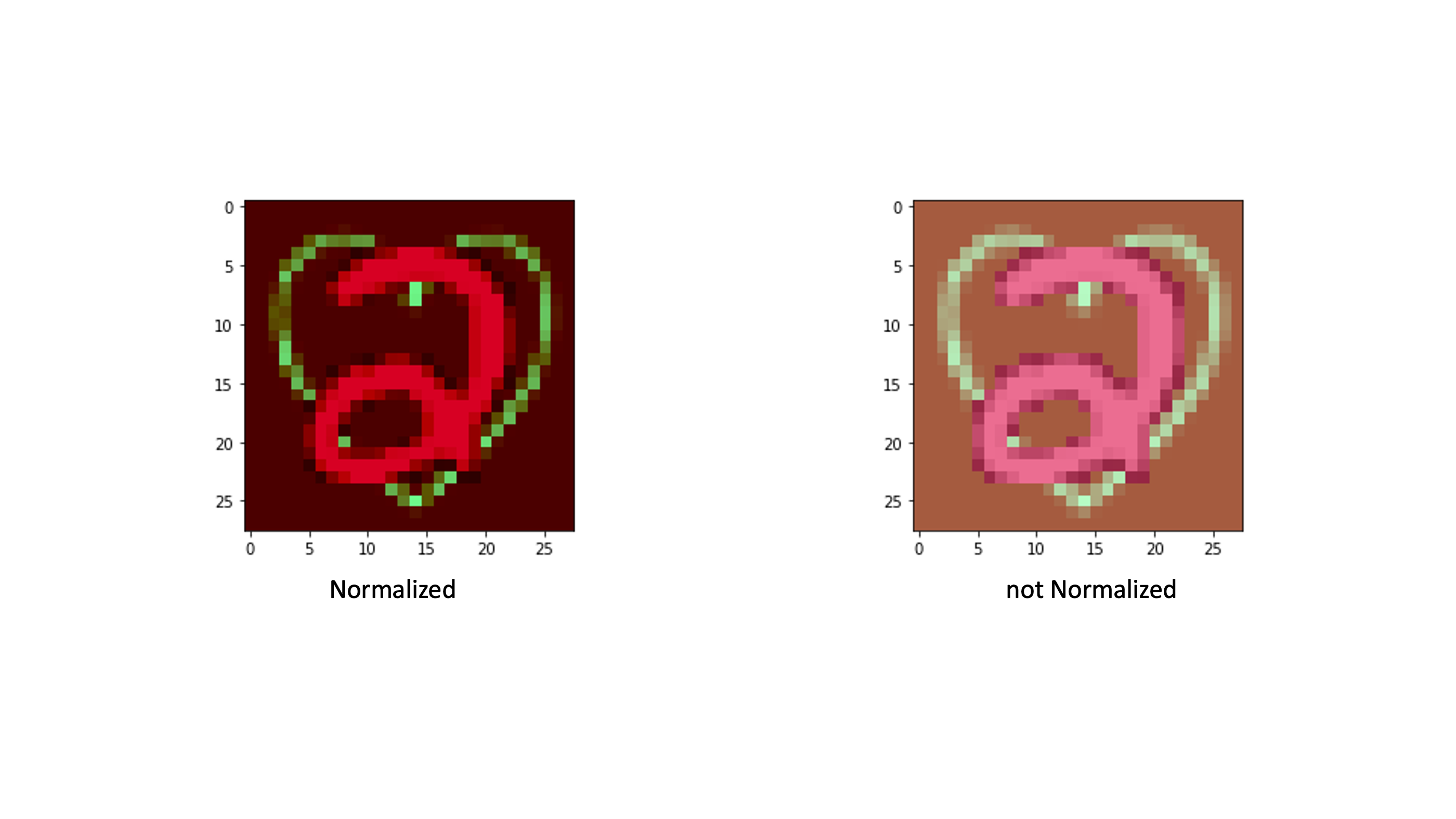
위 그림은 숫자 2에대한 데이터를 Normalization 전, 후를 비교하는 이미지다. 이 프로젝트의 목표는 어떠한 숫자 이미지가 들어와도 예측하는 것이기 때문에 Normalization을 적용시킨 이미지를 trainning 하도록 했다.
GPU
print(torch.cuda.is_available())
dev = torch.device(
"cuda") if torch.cuda.is_available() else torch.device("cpu")
True
GPU 사용을 위해 정의 해준다.
Network
def conv_layer(chann_in, chann_out, k_size, p_size):
layer = nn.Sequential(
nn.Conv2d(chann_in, chann_out, kernel_size=k_size, padding=p_size),
nn.BatchNorm2d(chann_out),
nn.ReLU()
)
return layer
def vgg_conv_block(in_list, out_list, k_list, p_list, pooling_k, pooling_s):
layers = [ conv_layer(in_list[i], out_list[i], k_list[i], p_list[i]) for i in range(len(in_list)) ]
layers += [ nn.MaxPool2d(kernel_size = pooling_k, stride = pooling_s, ceil_mode=True)]
return nn.Sequential(*layers)
def vgg_fc_layer(size_in, size_out, keep_prob, xavier=True):
linear = nn.Linear(size_in, size_out)
if xavier :
torch.nn.init.xavier_uniform_(linear.weight)
layer = nn.Sequential(
linear,
nn.BatchNorm1d(size_out),
nn.ReLU(),
nn.Dropout(p = 1 - keep_prob)
)
return layer
class MyModule(nn.Module):
def __init__(self, keep_prob = 0.5, xavier = True):
super(MyModule, self).__init__()
# Conv blocks (BatchNorm + ReLU activation added in each block)
channels = [32, 64, 128]
self.layer1 = vgg_conv_block([3,channels[0]], [channels[0],channels[0]], [3,3], [0,0], 2, 2)
self.layer2 = vgg_conv_block([channels[0],channels[1]], [channels[1],channels[1]], [3,3], [0,0], 2, 2)
self.layer3 = vgg_conv_block([channels[1],channels[2]], [channels[2],channels[2]], [3,3], [1,0], 2, 2)
# FC layers
self.layer4 = vgg_fc_layer(channels[2], 1024, keep_prob = keep_prob,xavier = xavier)
self.layer5 = vgg_fc_layer(1024, 800, keep_prob = keep_prob, xavier= xavier)
# Final layer
self.layer6 = nn.Linear(800, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
vgg16_features = self.layer3(out)
out = vgg16_features.view(out.size(0), -1)
out = self.layer4(out)
out = self.layer5(out)
out = self.layer6(out)
return out

MNIST 이미지는 작은 사이즈의 이미지 이기 때문에 굳이 크고 깊은 네트워크를 구축할 필요가 없기 때문에 3-layer VGG Network를 구현했다.
Model Hyper parameter
- keep_prob
- xavier
총 파라미터 개수 : 287008
Prepare Trainning
구현하는데 시간이 가장 많이 들었던 구간이다. Tensorboard 시각화와, loss 시각화를 때문에 코드가 조금 지저분해졌지만 훈련과정을 직접 확인하고 볼 수 있어서 구현하고 매우 뿌듯함이 컸었다.
Early Stopping
class EarlyStopping:
"""주어진 patience 이후로 validation loss가 개선되지 않으면 학습을 조기 중지"""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
"""
Args:
patience (int): validation loss가 개선된 후 기다리는 기간
Default: 7
verbose (bool): True일 경우 각 validation loss의 개선 사항 메세지 출력
Default: False
delta (float): 개선되었다고 인정되는 monitered quantity의 최소 변화
Default: 0
path (str): checkpoint저장 경로
Default: 'checkpoint.pt'
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''validation loss가 감소하면 모델을 저장한다.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), 'model/'+self.path)
self.val_loss_min = val_loss
정말 필수 중에 필수 중에 필수적인 기능이다. 시간단축 및 model을 자동으로 저장하고, 최신화하고, 불러와주는 역할을 해준다.
fit
# model과 관련있는 함수들
def get_model(lr = 0.01, keep_prob = 0.5, xavier = True, weight_decay = 0.005):
model = MyModule(keep_prob, xavier)
optimizer = optim.Adam(model.parameters(), lr=lr, weight_decay = weight_decay)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, patience = 4)
return model.to(dev), optimizer, scheduler
'''
opt 인자를 이용해 train과 valid의 동작을 다르게 해준다.
train : return [loss, learning_rate]
eval : return [loss]
'''
def loss_batch(model, loss_func, xb, yb, opt=None):
out = []
loss = loss_func(model(xb), yb)
if opt is not None:
loss.backward()
opt.step()
opt.zero_grad()
out.append(opt.param_groups[0]['lr'])
out.append(loss.item())
return out
def fit(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path):
start = time.time()
train_loss = []
valid_loss = []
# earlystopping
early_stopping = EarlyStopping(patience = 8, verbose = True, delta=0.0001, path = path+'_checkpoint.pt')
# tqdm을 이용해 반복문 과정을 시각화 해준다.
for epoch in notebook.tqdm(range(epochs), desc = 'Epoch'):
model.train()
loss = []
for xb, yb in notebook.tqdm(train_dl, desc = 'train'):
lr, l = loss_batch(model, loss_func, xb, yb, opt)
loss.append(l)
print("[Epoch: %d], train avg_loss: %f" % (epoch, (avg_loss := sum(loss)/len(loss))))
train_loss.append(avg_loss)
# train 결과물 write to tensorboard
writer.add_scalar('{}/Loss/train'.format(path), avg_loss, epoch)
writer.add_scalar('{}/learning_rate'.format(path), lr, epoch)
model.eval()
loss = []
with torch.no_grad() :
for xb, yb in notebook.tqdm(valid_dl, desc = 'valid') :
l = loss_batch(model, loss_func, xb, yb)[0]
loss.append(l)
print("[Epoch: %d], valid avg_loss: %f" % (epoch, (avg_loss := sum(loss)/len(loss))))
valid_loss.append(avg_loss)
# valid 결과물 write to tensorboard
writer.add_scalar('{}/Loss/valid'.format(path), avg_loss, epoch)
# scheduler 및 earlystopping
scheduler.step(avg_loss)
early_stopping(avg_loss, model)
print('-'*50)
if early_stopping.early_stop:
print("Early stopping")
break
print("cost time :", time.time() - start)
writer.flush()
model.load_state_dict(torch.load('model/'+path+'_checkpoint.pt'))
return model, train_loss, valid_loss
optimizer는 가장 무난하다고 알려진 adam을 사용했다.
early_stopping과 scheduler는 한 세트나 다름없다. 각 함수의 patient를 보면
early_stopping.patient = 8
scheduler.patient = 4
로 설정을 했는데, 그 이유는 valid loss 가 4 epoch 동안 개선되지 않으면 scheduler를 통해 learning rate 를 1/10 만큼 감소시킨 뒤, 4번의 기회를 더 주고 그 안에 valid loss가 개선되지 않으면 stop을 하도록 하기 위해서 patient 의 차이가 4가 되도록 설정했다.
Data process
def get_data(train_ds, valid_ds, bs):
return (
DataLoader(train_ds, batch_size=bs, shuffle=True),
DataLoader(valid_ds, batch_size=bs * 2),
)
def preprocess(x, y):
return x.to(dev, dtype=torch.float), y.to(dev, dtype=torch.long)
class WrappedDataLoader:
def __init__(self, dl, func):
self.dl = dl
self.func = func
def __len__(self):
return len(self.dl)
def __iter__(self):
batches = iter(self.dl)
for b in batches:
yield (self.func(*b))
위에서 정의한 train_ds와 valid_ds을 batch_size만큼씩 꺼내며 GPU 로 설정해주는 함수다.
Visualization
def accuracy(data):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for xb, yb in notebook.tqdm(data) :
output = model(xb)
pred = torch.argmax(output, dim = 1)
correct += (pred == yb).sum()
total += yb.size(0)
print(correct, total)
print("avg acc: %f" % (100* correct/total))
return correct / total * 100
def loss_graph(train_loss, valid_loss) :
# 훈련이 진행되는 과정에 따라 loss를 시각화
fig = plt.figure(figsize=(10,8))
plt.plot(range(1,len(train_loss)+1),train_loss, label='Training Loss')
plt.plot(range(1,len(valid_loss)+1),valid_loss,label='Validation Loss')
# validation loss의 최저값 지점을 찾기
minposs = valid_loss.index(min(valid_loss))+1
plt.axvline(minposs, linestyle='--', color='r',label='Early Stopping Checkpoint')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
fig.savefig('model'+path+'-loss_plot.png', bbox_inches = 'tight')
print('lr : {}, keep_prob : {}, weight_decay : {}, layer : {}'.format(lr, keep_prob, weight_decay, layer))
시각화 및 성능 테스트를 하기위한 함수들
Tensorboard
writer = SummaryWriter('runs/3D_MNIST')
writer의 위치에 각 학습 과정 결과물을 저장하도록 한다.
루트 디렉토리에서 터미널에
tensorboard --logdir=runs
명령어를 친 뒤 텐서보드 를 켜서 확인

Hyper Parameters
# Cross entropy loss func
loss_func = nn.CrossEntropyLoss()
# hyper parameters
batch_size = 2048
epochs = 500
lrs = [0.001, 0.0005]
keep_probs = [0.85, 0.9]
xavier = True
weight_decays = [0.005, 0.001, 0.0005]
# Dataset 정리
train_dl, valid_dl = get_data(train_ds, valid_ds, batch_size)
train_dl = WrappedDataLoader(train_dl, preprocess)
valid_dl = WrappedDataLoader(valid_dl, preprocess)
grid search를 위해 각 hyperparameter들을 리스트로 설정한다.
Trainning
from itertools import product
train_acc = []
valid_acc = []
for lr, keep_prob, weight_decay in product(lrs, keep_probs, weight_decays) :
# graph, model이 저장될 path
path = 'HyperParams-{}_{}_{}'.format(lr, keep_prob, weight_decay)
model, opt, scheduler = get_model(lr = lr, keep_prob = keep_prob, xavier = xavier, weight_decay = weight_decay)
model, train_loss, valid_loss = fit(epochs, model, loss_func, opt, scheduler, train_dl, valid_dl, path = path)
loss_graph(train_loss, valid_loss)
print('lr : {}, keep_prob : {}, weight_decay : {} Score'.format(lr, keep_prob, weight_decay))
train_acc.append(accuracy(train_dl).item())
valid_acc.append(accuracy(valid_dl).item())
clear_gpu()
print('==='*30)
print('==='*30)
sklearn 의 gird_search를 product를 이용해 적용시켜주었다.
Best Score
batch_size = 2048 epoch = 27 lr = 0.001 keep_prob = 0.85 weight_decay = 0.005 train Acc : 93.42% valid Acc : 90.01%
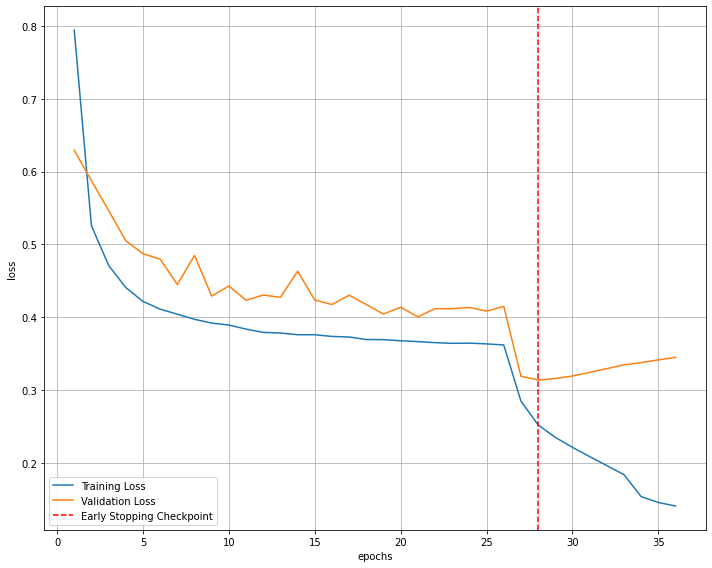
weight_decay vs dropout
둘의 실질적인 차이가 궁금했지만 교수님께 여쭈어봐도 모른다고 하셔서 일단 묻어두고 있었는데 이번 프로젝트를 통해 둘의 차이점을 대충 알아낸것같다.
수학적으로만 본다면 Weight_decay는 목소리가 큰 사람의 목소리 작게 만드는 것이고, Dropout은 목소리가 작은 사람의 목소리를 잘 들을 수 있도록 집중해서 보는것으로 볼 수 있다. 하지만 weight_decay는 전체 네트워크에 영향을 끼치는 파라미터고, Dropout은 Fully connected layer에만 영향을 미치기 때문에 일단 네트워크 전체가 FC layer가 아닌이상 영향력의 차이가 있음은 알 수 있다.
weight decay penalty

weight_decay를 낮게 잡은 경우 Loss 곡선이 마치 사이클로이드 모양으로 빠르게 감소되며 학습이 잘되지만, overfitting 구간에서 valid Loss가 매우 가파르게 증가하고 train Loss는 매우 가파르게 감소한다.
weight_decay를 높게 잡은 경우 Loss 곡선이 계단모양으로 느리지만 이쁘게 감소되는데 학습이 잘 안되고, overfitting구간에서 valid Loss가 미세하게 증가하며 train Loss또한 미세하게 감소한다.
dropout penalty

Keep_prob를 낮게잡을 경우 Train이 Valid보다 Loss가 높아졌다. 전체적인 Loss가 큰 상태로 시작되고 끝남. Overfitting 구간이 거의 없음.
keep_prob를 높게 잡을수록 Train, Valid 가릴 것 없이 전체적인 Loss가 낮아졌다. 그리고 미세하게 Overfitting을 억제하는 모습을 볼 수 있었다.
이 두 차이를 합쳐서 요약하면
전체적은 Loss값은 weight_decay를 통해 조절해 주고, overfitting이 시작되는 부분에대한 tunning은 keep_prob를 통해 조절해 주는게 가장 Best였다.
오답 확인
모델이 잘 못맞추는 케이스를 확인하기 위해 오답 이미지를 출력해보았다.

못맞추는 케이스는 3가지 경우로 보인다.
- Augmentation 과정에서 픽셀이 아예 뭉개져버린경우
- 데이터문제이므로 어쩔 수 없음.
- Augmentation 과정에서 그림이 회전하며 다른 숫자와 비슷하게 된 경우
- Translation equvariance 가 필요함. 하지만 모델의 한계라 어쩔 수 없음.
- 이미지 특징추출이 부족함.
- 아래그림의 2번째 경우.
Class weight
2와 5 그리고 6과 9를 헷갈려 하는 결과가 나왔기 때문에 [2, 5, 6, 9] class에 weight를 조금 실어주도록 했다.

어느 한 label에 weight를 준다 해도 전체 predict에 영향을 미치기 때문에 쉽게 최적점을 찾기가 너무 힘들었다. 값을 조절하니 오히려 성능이 안좋아지는 움직임을 보였다. 따라서 class weight는 적용시키지 않기로 했다.